8.3. Monte Carlo Localization
1. Illustration
MCL(Monte Carlo Localization)은 $bel(x_t)$를 praticle로 나타내는 localization algorithm입니다. 그림 8.11. 은 1차원 복도에서의 MCL예제입니다.
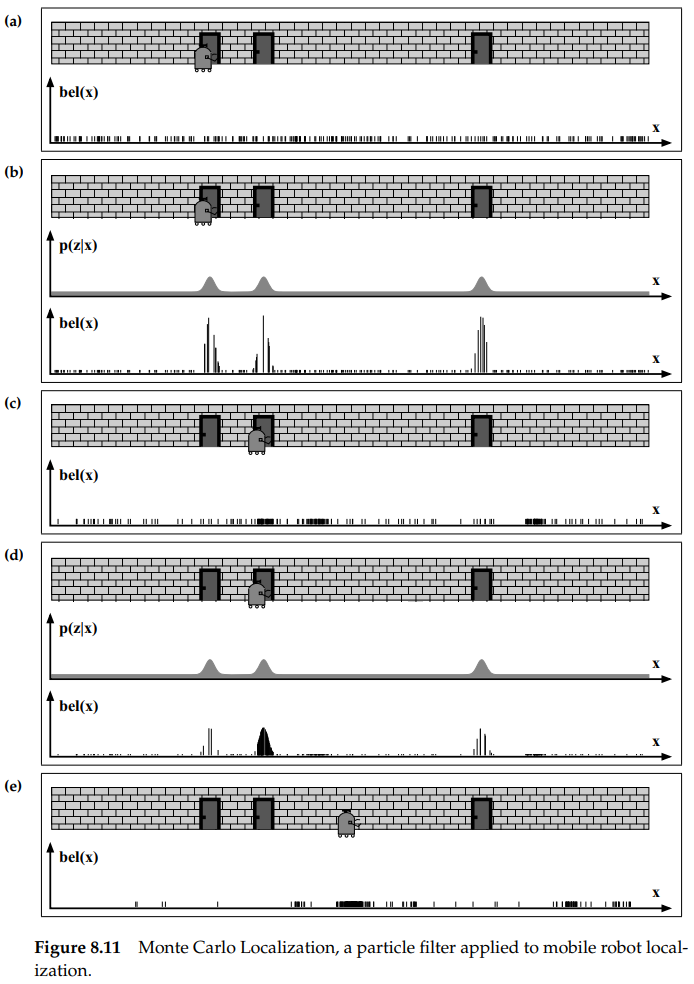
initial global uncertainty는 모든 pose space에 uniform하게 생성된 pose particle 집합을 통해 나타냈습니다. 로봇이 문을 감지했을 때, MCL은 그림 (b)와 같이 각각의 particle에 importance factors를 할당합니다. 각각의 particle의 높이는 importance weights를 나타냅니다. 여기서 중요한 점은 각각의 particle은 모두 (a)에서의 파티클과 같은데 가중치만 곱해졌다는 것입니다.
(c)는 로봇의 motion을 포함한 후 resampling한 뒤의 particle 집합을 보여줍니다. 이는 가중치가 모두 동일한 새로운 particle 집합을 만들지만, 로봇이 있을 것으로 추정되는 위치에는 더 많은 particle이 모여있습니다.
(d)에서 새로운 측정값은 non-uniform importance weight를 그 particle set에 할당합니다. 이때, 대부분의 확률 질량은 로봇이 있을 것으로 추정되는 두 번째 문에 집중되며, 위와 같은 과정의 반복을 통해 로봇이 점점 자신의 위치를 추정하게 됩니다.
2. The MCL Algorithm
table 8.2.는 table 4.3의 particle-algorithm filter를 대신하는 basic MCL algorithm을 보여줍니다.


basic MCL algorithm은 $bel(x_t)$를 $M$개의 particles의 집합인 $\chi _t = \chi _t = \left\{x_t^{[1]},x_t^{[2]}, ..., x_t^{[M]}, \right\}$로 나타냅니다.
table 8.2.에서 line 4는 motion model로부터 샘플링을 하는데, 출발 지점으로 생각되는 현재의 belief로부터의 particles를 이용합니다. line 5에 적용된 measurement model은 particle의 importance weight를 결정합니다. 초기의 belief $bel(x_0)$은 사전 분포 $p(x_0)$로부터 온 $M$개의 particles를 랜덤 하게 만드는 것에 의해 얻게 되고, uniform importance factor $M^{-1}$을 각각의 particle에 할당합니다.
3. Physical Implementations
그림 8.12는 MCL algorithm을 보여줍니다.

로봇의 path와 measurement는 (a)에 나타내었으며, MCL algorithm이 진행됨에 따라 생성된 sample 집합들은 (c)에 나타내었습니다. 여기서 굵은 선은 로봇의 true path를 나타내고, 점선은 control information에 기반한 path이며, 파선(dashed line)은 MCL algorithm에 의해 추정된 mean path입니다. 시간에 따른 예측된 샘플 집합 $\overline{\chi} _t$은 어두운 색깔의 점이고, 리샘플링 이후의 샘플 집합 $\chi _t$는 회색 점으로 나타냈습니다. 평균과 공분산은 (b)에 나타냈습니다.
그림 8.13은 실제 사무실 환경에서 MCL을 적용한 결과를 나타냅니다. 로봇은 여러개의 sonar range finders를 장착하였으며, 각각 5m, 28m, 55m를 움직였을 때의 결과를 보여줍니다.

4. Properties of MCL
MCL은 실질적으로 중요한 대부분의 어떤 분포도 approximate할 수 있습니다. 단지 어떤 분포의 parametric subset에 제한되지 않는다는 것입니다. particles의 개수를 늘리는 것은 approximation의 정확도에 영향을 줍니다. particles의 수 $M$은 우리가 계산의 정확도와 계산의 시간 사이에서 trade off 하도록 합니다. $M$을 설정하기 위한 일반적인 방법은 다음 $u_t$와 $z_t$ 쌍이 도착할 때까지 샘플링을 계속하는 것입니다. 이 방법으로, 이 implementation은 computational resources에 의해 조정되는데, 즉 프로세서가 좋을수록 더 나은 localization 결과가 나오게 됩니다(PC가 좋으면 다음 모션과 측정이 이루어지기 전까지 더 많은 샘플링을 하기 때문입니다.)
MCL의 또다른 장점은 non-parametric nature of the approximation에 관련되어 있습니다. MCL은 복잡한 multi-modal 확률 분포를 나타낼 수 있고, 그 분포들을 Gaussian-style 분포로 seamlessly 하게 blend 할 수 있습니다.
5. Random Particle MCL : Recovery from Failures
MCL은 global localization problem은 해결할 수 있지만, robot kidnapping 또는 global localization의 실패로부터는 recover할 수 없습니다. 이는 그림 8.13에서 꽤 명백하게 나타나는데, 로봇의 위치가 획득되면, 로봇이 실제로 있을 것으로 추정되는 위치에 있지 않은 particles는 점점 사라집니다. 일부 위치에서, particles는 하나의 pose로 단지 "생존"해 있기만 하는데, 만약 이 pose가 잘못된 경우 이 알고리즘은 recover를 할 수 없습니다.
실제로, MCL같은 어떤 확률적 알고리즘은 resampling step동안 correct pose 근처의 모든 particles를 실수로 무시해버릴 수 있습니다. 이 문제는 특히 particle의 숫자가 작을 때, particles가 매우 큰 volume에 걸쳐서 넓게 퍼져있을 때 더 문제가 됩니다.
다행히, 이 문제는 rather simple heuristic에 의해 해결될 수 있습니다. 이 heuristic의 아이디어는 particle sets에 랜덤한 particles를 더하는 것입니다. 이런 injection of random particles 같은 것은 수학적으로 그 로봇이 매우 작은 확률로 납치될 수 있다는 것을 가정함으로써 정당화될 수 있고, 따라서 motion model에서 fraction of random state를 만들어냅니다.
particles를 더하는 접근방법은 두 개의 의문점을 생기게 합니다. 첫 번째, 그 algorithm의 반복에서 얼마나 많은 particles들이 추가되어야 하는지, 두 번째, 어떤 분포에서 particles이 만들어져야 하는지 입니다. 우리는 각각의 반복에서 랜덤한 숫자의 particles를 추가할 수 있지만, 더 나은 방법은 localization performance의 추정에 기반하여 추가하는 것입니다.
이 아이디어를 적용하기 위한 방법 중 하나는 sensor measurements의 확률을 모니터링하는 것입니다.
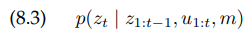
그리고 이 것을 average measurement probability와 관련시키는 것입니다. particle filters에서, 이 quantity의 approximation은 importance factor로부터 쉽게 얻을 수 있었는데, 따라서, 정의에 의해 importance weight는 이 확률의 확률적 추정(stochastic estimate)입니다.
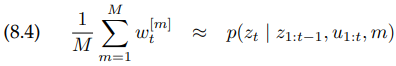
여기서 식 (8.4), average value는 상태로써 요구되는 확률을 approximate합니다. 이는 보통 여러 time step에 걸쳐 평균을 냄으로써 이 추정을 smooth 하게 만들기 위한 좋은 방법입니다.
localization failure말고, 왜 measurement probability가 작을 것이냐 하는 몇 가지 이유가 있습니다. sensor noise의 값은 비정상적으로 높거나, particles가 global localization phase동안 여전히 넓게 퍼져있을 수 있습니다. 이런 이유들로 인해, measurement likelihood의 short-tem average를 유지하고, random samples의 개수를 결정할 때, 이 값을 long-term average와 관계시키는 것이 좋습니다.
어떤 분포로부터 샘플이 결정되어야 하는가 하는 두 번째 문제에는 두 가지 방법이 있습니다. 하나는 pose space 전체에 대해 uniform distribution으로 그리고, 현재의 observation으로 가중치를 적용하는 것입니다.
하지만, 몇몇 모델은 measurement distribution에 대해 직접적으로 particles를 만드는 것이 가능합니다. 이런 sensor model의 예는 landmark detection model입니다. 이 경우 추가적인 particles는 observation likelihood를 따라 분포된 위치에 직접적으로 놓일 수 있습니다.
table 8.3은 random particles를 추가하는 MCL algorithm의 변형을 보여줍니다.

이 algorithm은 adaptive이고, likelihood $p(z_t | z_{1:t-1}, u_{1:t}, m)$의 short-term과 long-term average를 track 합니다. 이 algorithm의 처음 부분은 table 8.2의 MCL algorithm과 같습니다. 새로운 poses는 line 5에서 motion model을 이용하여 샘플링되며, importance weight는 line 6에서의 measurement model을 따르는 집합입니다.
Augmented_MCL은 line 8에서 empirical measurement likelihood를 계산하고, line 10과 11에서 이 likelihood의 short-term과 long-term averages를 유지합니다. 위 algorithm에서, $0 \leq \alpha _{slow} \ll \alpha _{fast}$ 입니다. parameters $\alpha _{slow}, \alpha_{fast}$는 각각 long-term, short-term의 평균을 추정하는 exponential filters의 decay rates입니다.
이 algorithm의 가장 중요한 부분은 line 13인데, resampling process동안, random sample은 새로운 확률, 식 (8.5)에 의해 추가됩니다.

random sample을 추가하는 확률은 measurement likelihood의 short-term average와 long-term average의 차이를 고려합니다. 만약 short-term likelihood가 long-term likelihood보다 좋거나 같다면, random sample은 생성되지 않습니다. 만약 short-term likelihood가 long-term likelihood보다 나쁘다면, 해당 값에 비례하여 random samples가 추가됩니다. 이런 방법으로, 갑작스러운 measurement likelihood의 감소는 random samples의 증가를 유발합니다. exponential smoothing은 좋지 않은 localization 결과가 있는 순간의 sensor noise를 잘못 판단하는 것을 방지합니다.

그림 8.16은 실제로 agumented MCL Algorithm을 적용한 그림입니다. 3x2m 크기의 경기장에서 카메라를 장착하고, 다리가 있는 로봇이 global localization과 relocalization을 하는 중의 particle sets을 보여줍니다. sensor measurement는 필드의 6개의 시각적 markers에 대한 상대적인 localization과 감지에 대응됩니다. detection의 likelihood를 계산하기 위해서는 table 6.4의 알고리즘을 사용했습니다.
그림 8.16의 (a)부터 (d)는 global localization을 보여줍니다. 첫 번째 marker detection에서, 그림 (b)의 detection을 따라 모든 가상의 particles이 그려집니다. 이 step은 measurement probability의 short-term average가 long-term correspondent보다 훨씬 더 나쁜 경우입니다. 몇 번의 detection 후에, particles는 (d)와 같이 로봇의 위치 근처에 모이게 되고, measurement likelihood의 short, long-term averages 모두 증가하게 됩니다. localization에서 이 단계까지 오면, 로봇은 단지 그 위치를 tracking 하게 되고, observation likelihood는 더 높아지며, 단지 몇 개의 random particles만 가끔 추가됩니다.
위 경기장에서 로봇으로 축구를 한다고 했을 때, 심판에 의해 로봇이 다른 위치에 놓이게 되면 measurement probability는 떨어지게 됩니다. 새로운 위치에서의 첫 marker detection은 smoothed estimate $w_{fast}$가 여전히 높기 때문에 아직 어떠한 새로운 추가 particles를 만들지 않은 상태입니다(그림 (e)를 보세요). 새로운 위치에서 몇 개의 marker detections가 관측되고 나면, $w_{fast}$는 $w_{slow}$보다 훨씬 빠르게 감소하며 random particles가 생성됩니다(그림 (f)와 (g)를 보세요). 마지막으로, 로봇이 (h)에서와 같이 성공적으로 relocalize하게 되면, 위에서 설명한 MCL은 납치를 당했을 때도 살아남을 수 있다는 것을 보여줍니다.
6. Modifying the Proposal Distribution
MCL proposal mechanism은 MCL을 비효율적으로 만들 수도 있습니다. 챕터 4.3.3에서, particle filter는 motion model을 proposal distribution으로써 사용했는데, 이때 particle filter는 그 proposal distribution과 preceptual likelihood의 곱을 근사한 것을 구했습니다. 여기서 proposal distribution과 target distribution의 차이가 클 수록, 더 많은 샘플을 필요로 합니다.
이로 인해 MCL에서 failure mode가 유도되는데, 만약 우리가 noise가 전혀 없는 완벽한 센서를 사용한다면, 즉 로봇의 항상 정확한 pose에 대한 정보만을 주는 센서라면, MCL은 실패하게 될것입니다. localization에 대한 충분하지 못한 정보를 주는 noise-free 센서의 경우이더라도 마찬가지입니다.
이를 해결하는 방법은 꽤 간단한데, 인위적으로 센서의 noise를 inflate하는 것입니다. 하지만 이 inflation은 단지 measurement uncertainty뿐 아니라 particle filter algoritm의 approximate nature에 의한 uncertainty까지 수반된다고 생각할 수 있습니다.
이 대안으로는, sampling process를 수정하는 것입니다. 이 아이디어는 모든 particles의 작은 일부분에 대해, motion model과 measurement model의 역할을 바꾸는 것입니다. 즉, 원래는 motion model에 의해 particles이 만들어졌지만, measurement model을 이용하여 particles를 만드는 것입니다.

그리고, importance weight는 다음과 같이 계산됩니다.

이 새로운 sampling process는 원래의 particle filter에 대한 적절한 대안입니다. 따로 놓고 보면, particles를 만들 때 이전에 있던 모든 history를 완전히 무시하기 때문에 충분하지 않을 수 있습니다. 하지만 원래의 particle filter에서 만든 particles의 일부와 새로운 방법으로 만든 particles의 일부를 merge 하기 때문에 꽤 적절하다고 볼 수 있습니다.
이 결과의 알고리즘은 MCL with mixture proposal distribution 또는 Mixture MCL이라고 합니다. 실제로, 이는 새로운 process로 5%정도의 작은 particles를 만드는 경향이 있습니다.
하지만, 이 아이디어는 $p(z_t | x_t)$로부터 샘플링 하는것과 importance weight를 계산하는 부분 때문에 적용하기 꽤 어렵습니다. measurement model로부터 샘플링하는 것은 이 model의 inverse가 샘플링하기 쉽도록 closed form solution을 가져야 한다는 것입니다.
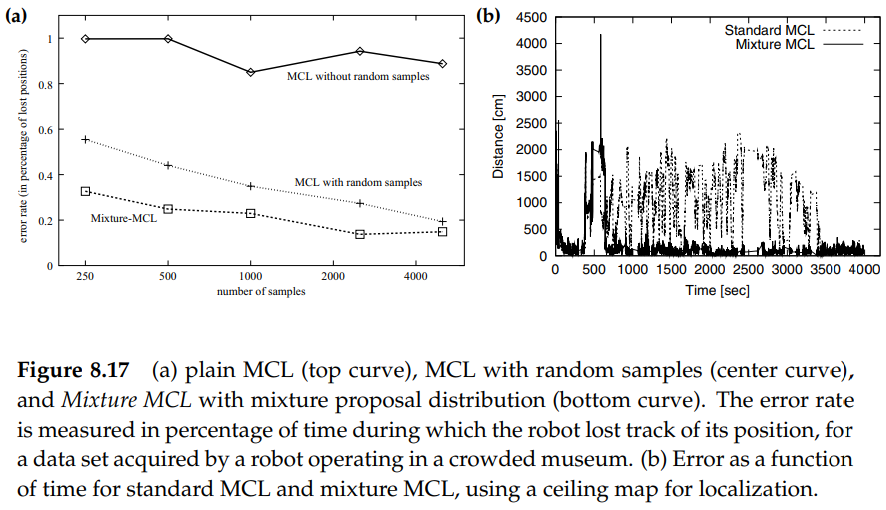
너무 깊게 들어가지 않고, 위의 두 step 모두 단지 추가적인 approximations만 있으면 적용될 수 있다고 하겠습니다. 그림 8.17은 MCL, MCL augmented with random samples, Mixture MCL의 비교를 보여줍니다.
7. KLD-Sampling : Adapting the Size of Sample Sets
beliefs를 나타내기 위해 사용된 sample sets의 크기는 particle filters의 효율성을 위한 중요한 파라미터입니다. 지금까지 우리는 지금까지 단지 고정된 크기의 sample sets를 이용해 particle filters에 대해 얘기했습니다. MCL에서의 sample depletion로 인한 발산을 피하기 위해, 우리는 큰 수의 sample sets를 선택해야 했는데, 이는 computational resources를 낭비할 수 있습니다. 그림 8.13의 경우 100,000개의 particles를 사용했는데, 그림 8.13의 (a)와 같이 초기에는 많은 수의 particles이 필요합니다. 하지만 localization이 진행되면서 로봇이 자신이 어디에 있는지 한 번 알고 나면 일부분의 particles만으로도 로봇의 위치를 추정하기에 충분한 것을 볼 수 있습니다.
KDL-sampling은 시간에 따라 particles의 수를 조절하는 MCL의 변형입니다. KLD-sampling의 아이디어는 sample-based approximation quality에 대한 통계적 경계에 기반한 particles의 수를 결정하는 것입니다. 더 자세히, particle filter의 각각의 반복에서, KLD-sampling은 true posterior(사후 확률)과 sample-based approximation 사이의 오차가 $\varepsilon$보다 작을 확률을 $1-\delta$로 하여 particles의 수를 결정합니다.
KLD-sampling algorithm은 table 8.4에 나타내었습니다. 이 알고리즘은 이전의 sample set과 map, 가장 최근의 control과 measurement를 입력 값으로 취합니다.

MCL과 대조적으로, KLD-sampling은 가중치가 적용된 샘플을 입력으로 취합니다. 즉, 샘플 집합 $\chi _{t-1}$은 아직 리샘플이 되지 않았다는 것입니다. 추가적으로, 이 알고리즘은 통계적 오차 경계(statistical error bound) $\varepsilon$과 $\delta$를 필요로 합니다.
간단히 말해서, KLD-sampling은 line 16에서의 통계적 경계까지 샘플을 계속 만든다는 것입니다. 이 경계는 particles에 의해 covered 된 상태 공간의 "volume"입니다. particles에 의해 covered된 이 volume은 3차원 공간에 겹쳐진 히스토그램 또는 grid에 의해 측정됩니다. 히스토그램 $H$에서의 각각의 bin은 가장 최근의 하나의 particle에 의해 점유되거나(occupied) 비어있게 됩니다. 초기에, 각각의 bin은 line 4에서 6을 통해 비어있는 집합으로 초기화됩니다. line 8에서, 하나의 particle은 이전의 샘플 집합으로부터 그려지게 됩니다. 이 particle에 기반해서, 새로운 particle이 예측되고 가중치가 적용되며, line 9~11을 통해 MCL처럼 새로운 샘플 집합에 포함되게 됩니다.
line 12~19는 KLD-sampling의 key idea를 적용합니다. 만약 새롭게 생성된 particle이 히스토그램에서 비어있는 bin의 영역에 들어가게 되면, 비어있지 않은 bin의 개수인 $k$는 증가하게 되고, 그 bin은 비어있지 않다고 표시됩니다. 따라서, $k$는 최소한 한 개의 particle로 채워진 histogram bin의 개수를 나타냅니다. 이 $k$는 line 16에서 결정된 통계적 경계만큼 a crucial role을 play 합니다. $M_{\chi}$는 이 경계에 닿기 위해 필요한 particles의 개수를 give 합니다. 주어진 $\varepsilon$과 $M_{\chi}$는 비어있지 않은 bin의 수인 $k$에서 거의 선형이며, 비선형 term은 $k$가 증가함에 따라 무시할만하게 됩니다. $z_{1-\delta}$는 $\delta$에 기반합니다. 이 값은 정규 분포에서 $1-\delta$ 이상의 분위수를 나타냅니다.
이 알고리즘은 $M$이 $M_{\chi}$와 user-defined 최솟값 $M_{\chi min}$을 초과할 때까지 새로운 particles를 생성합니다. threshold $M_{\chi}$는 $M$의 moving target으로 사용됩니다. 더 많은 샘플 $M$이 생성될수록, 히스토그램의 더 많은 bin $k$는 비어있지 않게되고, $M_{\chi}$는 더 커지게 됩니다.
실제로, 이 알고리즘은 다음의 이유 기반하여 종료됩니다. sampling의 초기 부분에서, 가상적으로 모든 bin들은 비어있기 때문에 $k$는 대부분의 새로운 샘플이 증가함에 따라 같이 증가하게 되고, 따라서 threshold $M_{\chi}$도 커지게 됩니다. 하지만, 시간이 지나면서 더 많은 bins가 비어있지 않게 되면, $M_{\chi}$는 단지 가끔씩 증가하게 될 것입니다. $M$은 각각의 새로운 샘플과 같이 계속 증가하기 때문에, 마침내 $M$은 경계 조건 $M_{\chi}$에 도달하여 샘플링이 멈추게 될 것입니다.
tracking을 진행하는 동안, particles이 적은 수의 각각 다른 bins에 집중되어있기 때문에 KLD-sampling은 더 적은 샘플들을 생성합니다. 히스토그램은 particle 분포 그 자체에는 영향이 없고, 단지 complexity나 volume, belief를 측정하기 위해 사용됩니다. 각각의 particle filter 반복의 마지막에서는 grid가 무시됩니다.
그림 8.18은 KLD-sampling을 사용한 일반적인 global localization을 진행하는 동안의 sample set의 크기입니다.
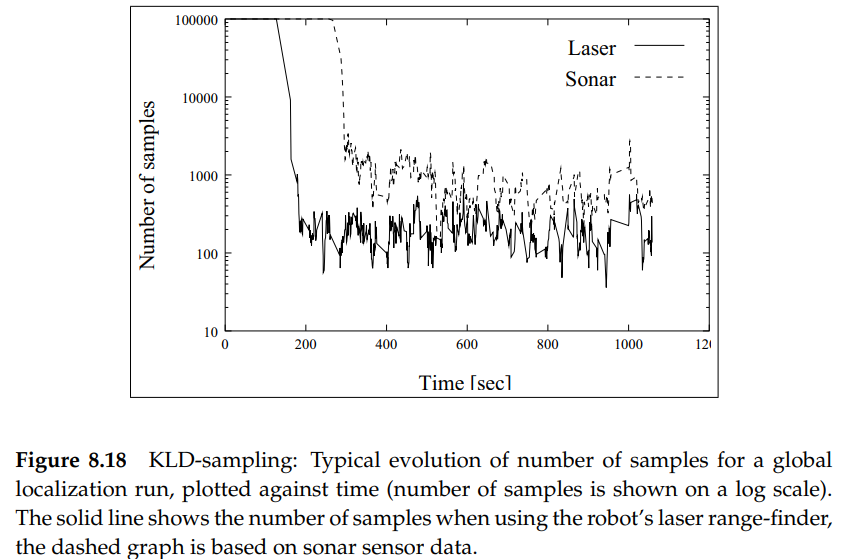
이 그림은 로봇이 초음파 센서, 레이저 센서를 사용한 경우의 그래프를 보여줍니다. 두 경우 모두, 알고리즘은 초기 localization에서는 많은 수의 sample을 선택하지만, 로봇이 localization 되고 나면, 훨씬 적은 수의 particles을 사용하는 것을 볼 수 있습니다. global localization에서 position tracking으로의 transistion이 얼마나 빠른가 하는 것은 환경의 종류와 센서의 정확도에 의존합니다. 이 예제에서는, 레이저 센서가 더 정확하므로 transistion이 더 빠르다는 것을 보여줍니다.
그림 8.19는 KLD-sampling과 고정된 sample 수의 MCL sampling의 근사 오차를 비교한 결과입니다. 여기서의 근사 오차는 다양한 숫자의 샘플들에 의해 생성된 belief와 "optimal" belief사이의 Kullback-Leibler distance로 측정하였습니다. 여기서 "optimal" beliefs는 실제로 position estimation에 필요한 것보다 더 큰 200,000개의 sample로 MCL을 실행하여 생성되었습니다.

예상대로, 두 방법 모두 더 많은 샘플을 사용할수록, 근사 오차가 더 작아지는 것을 볼 수 있습니다. 위 그래프에서 볼 수 있듯이, 고정된 샘플 수 접근법은 KL-distance가 0.25 밑으로 수렴하기 위해서는 약 50,000개의 samples를 필요로 합니다. 더 큰 오차는 일반적으로 particle filter가 발산하며, 로봇이 localize 할 수 없다고 나타냅니다. 여기서 각각의 data point는 오차 경계 $\varepsilon$을 0.4부터 0.015 사이에서 변화시켜서 얻은 결과입니다. KLD-sampling은 단지 약 3,000개의 샘플만 사용해도 작은 오차로 수렴하게 됩니다. 이 그래프는 KLD-sampling이 optimal belief를 정확하게 추적하는 것을 보장하지는 않는다는 것도 보여줍니다. KLD-sampling 그래프에서 왼쪽의 data points는 KLD-sampling이 너무 loose 한 오차 경계로 인해 발산하는 것을 나타냅니다.