AMCL 패키지를 수정하여 성능 개선해보기
이번 포스트를 읽기 전에, 다음 포스트들을 먼저 읽는 것을 권장합니다. 1~4의 포스트의 내용을 다 알고있다는 전제 하에 이 번 포스트를 작성하였습니다.
4. AMCL
Bayes Filter의 공식에 대해 더 알고싶다면 아래 포스트를 참조하세요
아래 두 포스트는 선택사항입니다. 읽으시려면 3.Particle Filter 이후에 읽는 것을 권장합니다.
이번 포스트는 ROS에서 제공하는 Navigation 패키지를 사용 중 발견한 문제점과 그 문제를 해결하는 방법에 대한 내용입니다. 이 내용은 ICS 2021 정보 및 제어 심포지엄에 "특징이 적은 환경에서의 AMCL 성능 향상을 위한 리샘플링 기법"으로 투고되었습니다.
기존 AMCL의 문제점
제가 실험한 환경에서의 AMCL의 문제점은, 오차가 누적될 경우 이를 거의 보정하지 못한다는 점입니다. AMCL 알고리즘 자체가 실시간으로 오차를 조금씩 보정해주긴 하지만, 만약 이 오차가 누적되어 현재 예상 위치를 벗어나버리는 경우, 기존 알고리즘을 통해서는 로봇이 이를 스스로 해결하는 것은 거의 불가능하다는 실험 결과를 확인했습니다.
제가 실험한 환경은 다음과 같이, 특징(feature)이 적은 약 30m정도의 긴 복도입니다. 빨간 삼각형 위치에서 시작하여, 초록색 별표로 나타낸 목적지까지 가는 내비게이션을 실행해봤습니다.

주행 결과, 다음과 같은 오차가 생겼으며, 이를 보정하지 못해 내비게이션에 실패하였습니다. 약 20번의 실험 결과, 단 한번도 목표지점에 도달하지 못했습니다.

실험 결과, 평균 75cm정도의 오차를 보였으며, 이는 약 30m주행거리에 비하면 2.5%정도의 오차입니다. 별로 큰 오차는 아니라고 볼 수도 있지만, 기존의 AMCL은 이를 보정하지 못하였습니다.
문제 해결을 위한 고찰
이런 환경에서 주행할 때의 문제점은, 특징이 적기 때문에 현재 위치를 정확하게 파악하기 어렵다는 점입니다.
다음 그림을 보겠습니다.

복도에서 주행을 하면, 가장 오른쪽의 그림과 같이 대부분의 파티클이 높은 가중치를 갖게됩니다. 즉, 로봇이 어떤 위치에 있더라도 현재 로봇의 위치에 대한 신뢰도가 높아지게 되고, 이에 따라 파티클은 한 군데에 모이게 되며, 결과적으로는 위치 오차를 보정하기가 어렵게 됩니다.
파티클이 한 군데에 모이게 되면 위치 보정이 어려운 이유는, 파티클 필터는 현재 존재하는 파티클을 기반으로 다음 위치를 예측하기 때문입니다. 즉, 파티클이 제대로 된 위치에 없다면 prediction에서 오차가 생기게 될 것이고, 파티클 필터에서의 correction step은 prediction step에서의 파티클 중에서만 리샘플링을 하므로, 결과적으로는 위치 추정의 오차를 보정하지 못하게 됩니다.
Probablistic Robotics책에서는 이와 비슷한 문제를 해결하기 위해 다음과 같은 알고리즘을 제시합니다.

위 알고리즘은 실시간으로 로봇의 위치에 대한 파티클의 평균 가중치를 구하고, 이에 따라 랜덤한 샘플을 생성할지를 결정하는 알고리즘입니다. 현재 위치에 대한 신뢰도가 높다면 평균 가중치인 $w_{avg}$가 높아집니다. 그렇지 않다면 $w_{avg}$는 낮아지게 됩니다. $w_{avg}$의 변화에 따른 $w_{slow}$와 $w_{fast}$의 그래프의 개형은 다음과 같습니다.

위 그래프는 $w_{avg}$를 작은 값으로 증감시켰을 때의 그래프입니다. 알고리즘의 line 13을 보면 $1-\frac{w_{fast}}{w_{slow}}$가 양수인 경우에만 해당 값의 확률로 랜덤한 샘플을 생성하는데, 이 값이 양수가 되려면 $w_{slow}$가 $w_{fast}$ 보다 커야만 가능하며, 이 구간은 $w_{avg}$가 빠르게 감소하는 구간입니다. 즉, 랜덤한 샘플을 생성하기 위해서는 현재 위치 추정에대한 오차가 커야한다는 것입니다. 이는 꽤 직관적인 결과입니다. 지금 위치가 정확하다면 굳이 랜덤한 샘플을 생성할 필요가 없겠지요
$w_{avg}$의 변화에 따른 $1-\frac{w_{fast}}{w_{slow}}$의 그래프는 다음과 같습니다.

복도처럼 특징이 적은 환경에서 주행을 하면, 대부분의 파티클이 높은 가중치를 갖게됩니다. 따라서 table 8.3의 line 8에서의 $w_{avg}$가 높아지게 됩니다. 따라서, 랜덤한 샘플이 생기지 않게 됩니다.
그러나 복도가 끝나게 되면 이제 오차가 꽤 커지게 되므로 오차 보정을 위해 랜덤한 샘플이 생겨야 하는데, 실험 결과 랜덤한 샘플이 생기지 않았습니다.
참고로, 랜덤한 샘플을 생성하기 위해서는 AMCL 패키지에서 다음 파라미터들을 설정해줘야 합니다. 기본값은 0입니다. 권장하는 값은 alpha_fast는 0.1, alpha_slow는 0.001입니다.
- recovery_alpha_slow (double, default: 0.0 (disabled))
- recovery_alpha_fast (double, default: 0.0 (disabled))
위의 파라미터를 설정했는데도 불구하고 랜덤한 샘플이 생기지 않은 이유는, 충분한 $w_{avg}$의 감소가 이루어지지 않았기 때문이었습니다. 실험을 더 해본 결과, 다음 그림과 같은 정도의 오차가 있어야 랜덤한 샘플이 생성되는것을 확인했습니다.

파티클이 뭉쳐있는 부분이 있고, 따로 몇 개의 파티클이 있는것을 확인할 수 있습니다. 따로 떨어진 파티클들이 랜덤하게 생성된 파티클입니다.
즉, 위와 같은 정도의 오차가 없다면 랜덤한 파티클이 생성되지 않습니다. 위 사진은 제가 일부러 오차를 만들기 위해 로봇을 조작한 것이며, 내비게이션 알고리즘 실행 시에는 이정도의 오차는 거의 생기지 않습니다. 다음 영상은 Pioneer 3dx를 사용한 결과입니다.
AMCL 패키지를 수정하여 성능 개선해보기
serviceapi.nmv.naver.com
또한, 이렇게 오차가 생긴다고 해도, $w_{avg}$는 다시 금방 증가하게 되었고, 따라서 랜덤한 파티클이 다시 생성되지 않아 로봇의 위치 추정 오차를 보정하는 것이 거의 불가능했습니다.
또한, 랜덤한 파티클이 로봇의 근처에 생길 확률 또한 매우 낮습니다. 기존 알고리즘은 robot kidnap 문제의 해결을 위해 고안된 알고리즘입니다. 따라서, 새로운 파티클을 생성할 때, 로봇이 존재할 수 있는 모든 위치를 대상으로 랜덤하게 파티클을 생성합니다.
지금 목표는 약 2~3%정도의 오차를 보정하는 것이므로, 해당 범위 안에 파티클이 있어야 이 오차를 보정할 수 있는데, 그러잖아도 랜덤한 "파티클이 생성될 확률이" 낮은데, 우리가 필요한 것은 생성된 파티클 중에서도 "적절한 위치에 생성된 파티클"이므로, 이 확률은 더더욱 낮아지게 됩니다.(위의 그림은 제가 임의로 로봇 근처에 랜덤 파티클이 생기도록 한 결과입니다. 이런 처리를 따로 해주지 않으면 지도상의 무작위 위치에 파티클이 생성됩니다.)
따라서, 이 문제를 해결하기 위한 제 생각은 다음과 같습니다.
1. robot kidnap problem은 고려하지 않습니다. 따라서, 현재 로봇의 근처에만 파티클이 생성되도록 합니다.
2. $w_{avg}$는 robot kidnap problem과 같은 상황이 아니면 충분히 감소하지 않습니다. 어차피 로봇의 센서와 휠 엔코더의 오차도 항상 고려해야 하므로, 고정된 값으로 랜덤한 샘플을 생성합니다.
3. 로봇의 센서와 휠 엔코더의 오차를 고려해서, 현재 로봇의 위치를 중심으로 가우시안 분포를 따라서 랜덤 파티클 생성하도록 합니다.
코드를 수정하여 문제 해결하기
원본 코드는 다음 링크에 있습니다.
https://github.com/ros-planning/navigation/tree/noetic-devel/amcl
먼저, 헤더파일부터 확인해봅니다.

제일 중요한 부분은 파티클 필터에 대한 내용이 있는 pf입니다.

이 헤더파일 중에서도 제일 중요한 부분은 pf.h입니다.
pf.h를 열어봅니다.
- pf.h

line 45에서 pf_vector_t 타입의 자료형을 사용하는데, 이는 "pf_vector.h"에 다음과 같이 정의되어있습니다.

이 구조체는 각 파티클을 $(x, y, \theta)$로 나타냅니다.
line 45의 함수는 초기의 파티클 분포를 설정에 대한 함수입니다.
line 49의 함수는 Table 8.2의 sample_motion_model에 해당됩니다.
line 54의 함수는 Table 8.2의 measurement_model에 해당됩니다.

다시 pf.h를 더 확인해보겠습니다. 이번에는 line 58부터 확인해봅니다.

line 59~67에서는 pf_sample_t라는 구조체를 정의합니다. 파티클 필터에서 사용하는 각각의 파티클을 의미합니다. 각각의 파티클은 pose와 weight를 갖습니다. pose는 위에서 말했다시피, $(x, y, \theta)$입니다.
line 71~86에서는 pf_cluster_t라는 구조체를 정의합니다. 이 구조체는 이름에서 유추해보면, 파티클이 여러개 모인 군집을 의미하는 것 같습니다. 주석에 잘 나타나 있으니 각 변수가 무슨 의미인지는 잘 알 수 있습니다.
이제 다음 부분을 살펴보겠습니다.

이 부분은 파티클의 집합을 정의한 부분입니다. table 4.3의 $\mathcal{X}$를 정의한 것으로 보입니다.

다음 부분을 살펴보겠습니다.
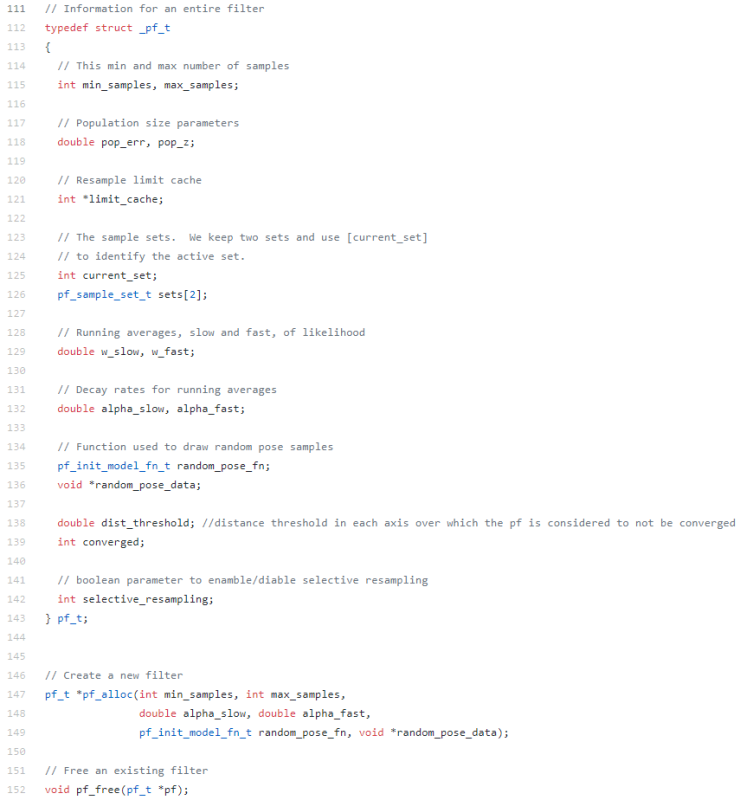
line 112~143은 AMCL에서 사용할 파티클 필터를 정의한 부분입니다. 필터에서 사용할 파라미터의 값 등이 정의되어 있습니다.
line 147~152는 파티클 필터를 동적 할당하여 생성 및 해제하는 부분입니다.
이 외 나머지 함수들은 아래와 같이 선언되어있습니다.


이제 pf.h는 다 확인하였으니, AMCL 알고리즘을 확인해보겠습니다. 우리가 자세하게 봐야 할 부분은 line 1119의 AmclNode::laserReceived()입니다. 이 함수는 레이저 스캐너의 데이터를 받고, 해당 데이터를 통해 파티클을 업데이트 하는 함수입니다.
amcl_node.cpp
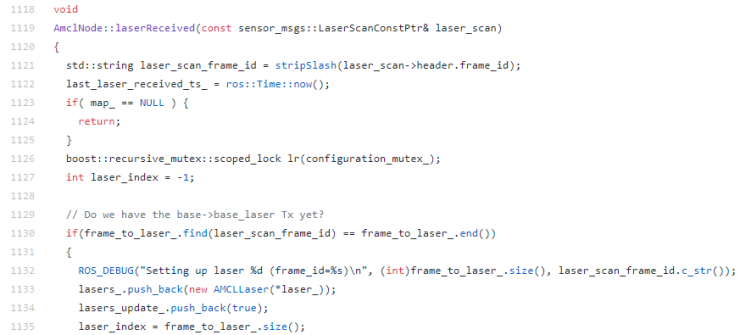
쭉~ 내려가서, line 1245를 확인해봅니다.

여기서 중요한 부분은 line 1245의 if 조건문입니다. 해당되는 인덱스의 레이저 데이터를 기반으로 파티클 필터를 실행하고, 파티클을 리샘플링하게 됩니다.
다시 더 내려가서, line 1318을 확인해봅니다.

line 1315까지는 가중치가 적용된 파티클 데이터들이 있는 상태이고, line 1318에서는 이 파티클들을 사용하여 리샘플링을 합니다. 따라서 우리는 line 1315와 1318사이에 코드를 추가해야합니다.

1326 ~ 1351 : 내비게이션을 실행하면 rqt 콘솔에서 해당 값들을 확인할 수 있습니다.
1354 : 현재 로봇의 위치를 중심으로 가우시안 분포를 따르는 랜덤 파티클을 생성합니다.
1355 ~ 1356 : 랜덤하게 파티클이 생성될 확률을 고정 값으로 할당합니다.
line 1355~1356에서 w_fast와 w_slow를 9.5와 10.0으로 할당한 이유는, 오차가 2.5%이었기 때문에 이 값의 2배를 할당했습니다. w_diff가 클수록(w_fast가 작아지고, w_slow가 커질수록) 랜덤한 샘플이 생성될 확률이 올라갑니다. 따라서 위치 추정의 오차도 더 잘 보정해줄 수 있지만, 컴퓨팅 파워가 좀 더 필요하게됩니다.
랜덤하게 파티클을 생성하기 위한 부분을 좀 더 자세히 보겠습니다. line 1354~1356입니다.
line 1354 : 현재 로봇의 위치를 중심으로 가우시안 분포를 따르는 랜덤 파티클을 생성합니다. AmclNode 클래스의 멤버함수이므로, AmclNode 클래스를 정의한 부분에서 해당 함수를 선해야합니다.
원본 코드입니다.

원본 코드를 수정하여, 아래와 같이 새로운 멤버 함수를 선언합니다.

이제 우리가 새로 추가한 함수를 정의해줘야 하는데, 그 전에 이 함수에서 사용할 전역 변수를 하나 선언해줍니다.
원본 코드입니다.

아래와 같이 전역 변수를 추가합니다.

함수의 정의는 코드의 맨 밑에쪽에 추가해줍니다.

1705 ~ 1720 : 가우시안 랜덤 함수를 계산하는 함수입니다.
1722 ~ 1744 : 가우시안 랜덤 함수를 통해 얻은 값을 특정 파티클의 pose에 추가하여 리턴합니다. 실험에서 얻은 로봇의 오차가 평균 약 75cm였으므로, 이에 해당하는 값 0.75를 현재 로봇의 pose에 더해서 사용합니다.
AmclNode::gaussianPoseGenerator() 함수가 리턴하는 파티클의 좌표값은 현재 로봇의 pose에 더해서 사용한다고 했는데, 현재 pose값을 저장하는 변수는 temp_x, temp_y, temp_t 입니다. 현재 pose를 가장 잘 나타내는 값은 가중치가 가장 큰 파티클이기 때문에, 이 값을 각 변수에 할당해줘야 합니다.
원본 코드입니다.

수정된 코드입니다.

실험해보기
이제 코드를 수정했으니, catkin_make 후 패키지를 실행하여 내비게이션이 얼마나 개선되나 확인해봅니다.
동영상 첨부가 안되네요. 아래 포스트의 맨 아래부분 영상을 확인하세요
https://blog.naver.com/staystays/222308710408
AMCL 패키지를 수정하여 성능 개선해보기
이번 포스트를 읽기 전에, 다음 포스트들을 먼저 읽는 것을 권장합니다. 1~4의 포스트의 내용을 다 알고있...
blog.naver.com
수정된 코드는 아래 파일을 참조하세요