[Do it!] 2. 분류하는 뉴런 만들기 - 이진 분류
이 포스트는 Do it! 정직하게 코딩하며 배우는 딥러닝 입문 pp.77~114를 참고하였습니다.
초기 인공지능 알고리즘과 로지스틱 회귀
퍼셉트론
퍼셉트론은 샘플을 이진 분류하기 위해 사용되는 알고리즘입니다. 퍼셉트론은 직선의 방정식을 사용하기 때문에 선형 회귀와 거의 같은 구조를 가지고 있습니다. 다만, 샘플을 분류하기 위해 계단 함수(step function)을 사용합니다. 그리고, 이 계단 함수를 통과한 값을 다시 가중치와 절편을 업데이트할 때 사용합니다. 이를 그림으로 나타내면 다음과 같습니다.

뉴런은 입력 신호들을 받아 다음 수식을 활용하여 출력 $z$를 만듭니다.
$w_1x_1 + w_2x_2 + b = z$
계단 함수는 $z$가 0보다 크거나 같으면 1, 작으면 -1로 분류합니다.
이 때, 1을 양성 클래스(positive class), -1을 음성 클래스(negative class)라고 합니다. 위 함수를 그래프로 그리면 다음과 같습니다.

이전 포스트에서는 입력 신호에 특성이 1개, 가중치가 1개, 절편이 1개인 모델을 사용했습니다. 즉, 당뇨병이 있는 환자들의 데이터인 몸무게, 키, 혈당 등 중에서 하나의 특성을 사용했던 것입니다. 이제부터는 여러 개의 입력 특성을 사용하기 위해 다음과 같은 모델을 사용합니다.

특성이 2개인 선형 함수는 다음과 같이 표기합니다. 아래 첨자 숫자는 $n$번째 특성의 가중치와 입력을 의미합니다. 이 책에서는 윗 첨자는 나오지 않는데, 윗 첨자는 보통 샘플을 의미합니다. 헷갈리지 않게 주의하세요.
특성이 $n$개인 선형 함수는 다음과 같이 표기할 수 있습니다.
$z = w_1x_1 + w_2x_2 + \dots + w_nx_n + b$
위 식을 간단하게 나타내면 다음과 같습니다.
$z = b + \sum_{i=1}^nw_ix_i$
아달린
아달린은 선형 함수의 결과를 학습에 사용합니다. 즉, 퍼셉트론에서 계단 함수를 통과한 값이 아닌, 계단 함수를 통과하기 직전의 값을 학습에 사용하고, 계단 함수를 통과한 값은 예측에만 사용합니다.

로지스틱 회귀
로지스틱 회귀는 아달린에서 조금 발전된 형태인데, 다음 그림과 같은 구조를 갖습니다.

로지스틱 회귀는 선형 함수를 통과시켜 얻은 $z$를 임계 함수에 보내기 전에 활성화 함수를 사용하여 이 값을 변형시킵니다. 이제부터 활성화 함수를 통과한 값을 $a$라고 하겠습니다. 로지스틱 회귀는 마지막 예측 단계에서 임계 함수를 사용하는데, 이는 아달린이나 퍼셉트론의 계단 함수와 비슷하지만, 입력으로 활성화 함수의 출력을 사용한다는 점이 다릅니다.
시그모이드 함수를 사용한 확률
로지스틱 회귀의 구조를 나타낸 그림에서, 가장 왼쪽에 있는 뉴런이 선형 함수이고, 선형 함수의 출력값은 다음과 같습니다.
$z = b + \sum_{i=1}^nw_ix_i$
그림에서 볼 수 있듯이, 선형 함수의 출력값 $z$는 활성화 함수에 의해 $a$가 됩니다. 여기서 사용된 활성화 함수는 $z$를 확률로 나타낼 수 있도록 0~1 사이의 값으로 바꿔주는 역할을 합니다. 이전에 말했듯이, 퍼셉트론은 이진 분류를 수행한다고 했는데, 로지스틱 회귀에서 이렇게 활성화 함수를 사용하면 선형 출력값을 통해 양성 샘플일 확률을 구할 수 있게 되는 것입니다.
시그모이드 함수
시그모이드 함수가 만들어지는 과정은 다음과 같습니다.
오즈 비 > 로짓 함수 > 시그모이드 함수
오즈 비
시그모이드 함수는 오즈 비(odds ratio)라는 통계에 기반하여 만들어집니다. 오즈 비는 성공 확률과 실패 확률의 비를 나타내는 통계이며, 다음과 같이 정의됩니다.
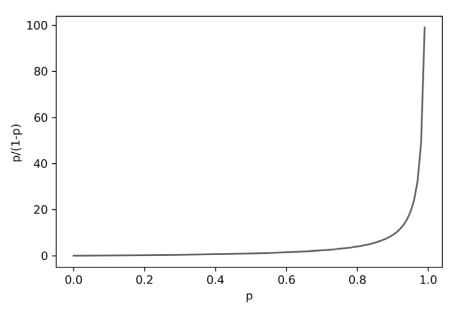
$OR(odds\; ratio) = \frac{p}{1-p}$
여기서 $p$는 성공 확률입니다. 그래프로 그리면 다음과 같습니다.
오즈 비에 로그(ln을 그냥 log 라고 하겠습니다) 함수를 취하여 만든 함수를 로짓 함수라고 합니다. 로짓 함수의 식은 다음과 같습니다.
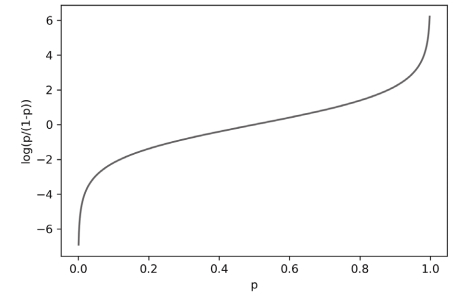
$logit(p) = log(\frac{p}{1-p})$
로짓 함수는 $p$가 0.5일때 0이 되고 $p$가 0과 1일때 각각 음의 무한대와 양의 무한대가 되는 특징을 갖습니다. 그래프는 다음과 같습니다.
로지스틱 함수
로짓 함수를 $z = log(\frac{p}{1-p})$라고 했을 때, 이 식을 $z$에 대한 식으로 바꾸면 다음과 같습니다.
$p = \frac{1}{1+e^{-z}}$
따라서, 그래프는 로짓 함수의 가로 축과 세로 축을 바꾼 형태를 나타내게 됩니다.
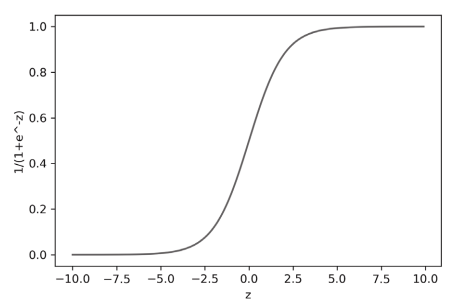
그래프의 모양이 S자 형태이므로, 시그모이드 함수라고도 합니다. 입력 값의 범위는 실수 전체이며, 출력 값은 0~1이므로, 실수 입력을 확률 값으로 바꿔줄 수 있는 특징을 가지고 있습니다.
최종적으로, 로지스틱 회귀를 그림으로 나타내면 다음과 같습니다.

퍼셉트론과 아달린에서는 예측 단계에서 계단 함수를 사용했습니다. 선형 함수의 출력이 0을 넘으면 양성, 0 미만이면 음성으로 분류했는데, 로지스틱 회귀에서는 선형 함수의 출력이 시그모이드 함수를 통과한 값, 즉 0~1사이의 값을 사용하기 때문에 0.5를 기준으로 양성과 음성을 분류합니다.
로지스틱 손실 함수를 경사 하강법에 적용하기
선형 회귀의 목표는 정답과 예상값의 오차의 제곱이 최소가 되는 가중치와 절편을 찾는 것이 목표였으므로, 경사 하강법을 사용하기 위해 제곱 오차 함수를 미분하여 적용해봤습니다. 하지만 로지스틱 회귀의 목표는 올바르게 분류된 샘플 데이터의 비율을 높이는 것입니다. 제곱 오차 함수는 미분이 가능하지만, 올바르게 분류된 샘플 데이터의 비율은 미분 가능한 함수가 아닙니다. 따라서, 비슷한 목표를 달성할 수 있는 다른 손실 함수인 로지스틱 손실 함수를 사용합니다.
로지스틱 손실 함수
로지스틱 손실 함수는 정보이론에서 사용하는 크로스 엔트로피(cross entropy)를 사용하여 구현합니다. 다중 분류에 사용하는 함수는 크로스 엔트로피 손실 함수라고 하고, 이진 분류에 사용하는 함수는 로지슽기 손실 함수라고 합니다. 로지스틱 손실 함수가 크로스 엔트로피 손실 함수의 부분집합이라고 보시면 됩니다. 로지스틱 손실 함수는 다음과 같이 정의됩니다.
$L = -(y\log(a) + (1-y)\log(1-a))$
위 식에서 $y$는 타깃 값이고, $a$는 활성화 함수의 출력 값입니다. 이진 분류는 양성(1), 음성(0)인 식으로 2개의 정답만 있습니다. 따라서 $y$는 0 또는 1인 경우밖에 없습니다. 따라서, $y$값에 따른 로지스틱 손실 함수는 $y$가 1인 경우(양성 클래스)에는 $-\log(a)$, 0인 경우(음성 클래스)인 경우에는 $-\log(1-a)$가 됩니다. 이를 그래프로 그리면 다음과 같습니다.
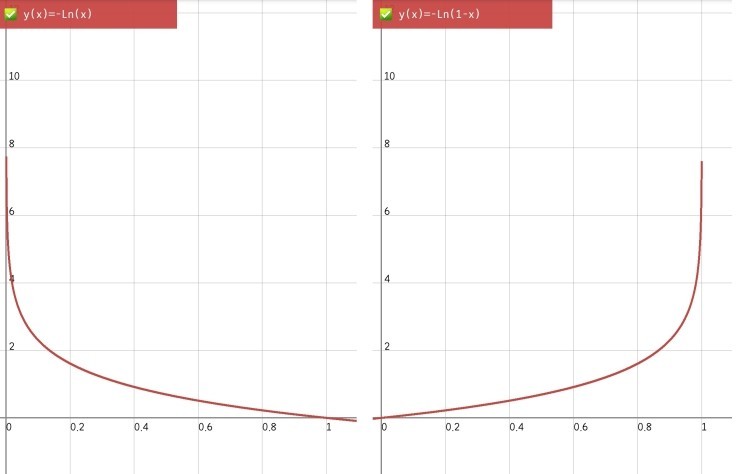
위의 손실함수를 최소화 하면, 자연스럽게 $a$는 우리가 원하는 값으로 이동하게 되는 것을 알 수 있습니다. 왼쪽 그래프의 경우, 즉 $y = 1$인 경우, 손실 함수가 감소하는 방향을 따라가면 $a$는 양성 타깃 값인 1에 가까워지고, 오른쪽 그래프, 즉 $y = 0$인 경우, 손실 함수가 감소하는 방향을 따라가면 $a$는 음성 타깃 값인 0에 가까워집니다. 이제 함수가 감소하는 방향을 따라가기 위해 위 그래프를 미분하면 될 것 같습니다. 그리고 이전과 마찬가지로 양의 기울기와 음의 기울기를 모두 빼주면 되겠네요.
로지스틱 손실 함수의 미분
앞에서 말했듯이, 역전파에서 최종적으로 우리가 계산하고 싶은 것은 오차를 가중치와 절편으로 미분한 결과입니다. 하짐나 로지스틱 손실 함수는 $a$에 대한 식이고, 이를 바로 $w$나 $b$에 대해 미분하면 너무 복잡하므로, 연쇄법칙을 사용합니다.
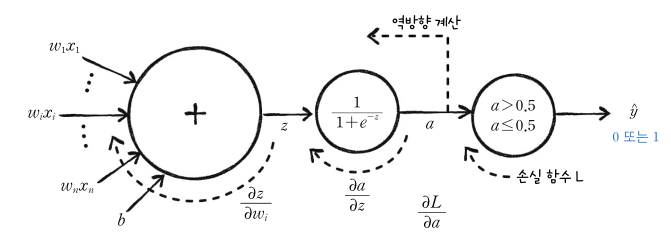
손실 함수를 $w$나 $b$에 대해 미분하기 위해서는 먼저 손실 함수를 $a$에 대해 미분하고, $a$를 $z$에 대해 미분하고, $z$를 $w$나 $b$에 대해 미분한 후, 연쇄법칙을 적용하여 모두 곱하면 됩니다. 이 과정을 그림으로 나타내면 다음과 같습니다.
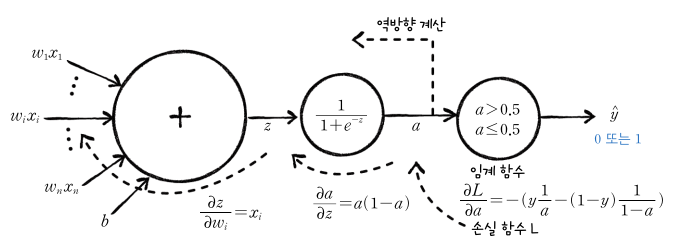
따라서 최종적으로, 손실 함수를 $w$와 $b$에 대해 미분한 값은 다음과 같습니다.
$\frac{\partial L}{\partial w_i} = \frac{\partial L}{\partial a}\frac{\partial a}{\partial z}\frac{\partial z}{\partial w_i}=-(y\frac{1}{a}-(1-y)\frac{1}{1-a})a(1-a)x_i$
$=-(y(1-a) - (1-y)a)x_i$
$= -(y-ya-a+ya)x_i $
$= -(y-a)x_i$
$\frac{\partial L}{\partial b} = \frac{\partial L}{\partial a}\frac{\partial a}{\partial z}\frac{\partial z}{\partial b}=
-(y\frac{1}{a}-(1-y)\frac{1}{1-a})a(1-a)$
$=-(y(1-a) - (1-y)a)$
$= -(y-ya-a+ya) $
$= -(y-a)$
이렇게 연쇄법칙을 사용하여 미분하는것을 보면, 그래이디언트가 전달되는 모습이 잘 보이게 됩니다. 이렇게 미분이 연쇄 법칙에 의해 진행되는 구조를 "그래이디언트가 역전파된다"라고 합니다.
손실 함수의 그래프를 보면, 경사 하강법과 비슷하게 기울기가 음수인 경우에는 음의 기울기를 빼서 가중치가 1로 다가가야 하고, 기울기가 양수인 경우에는 기울기를 빼서 가중치가 0으로 다가가야 하므로, 가중치를 빼서 업데이트 하면 됩니다. 따라서, $w$와 $b$는 다음과 같이 업데이트 해야합니다.
$w_i = w_i - \frac{\partial L}{\partial w_i} = w_i + (y-a)x_i$
$b = b - \frac{\partial L}{\partial b} = b + (y-a)$
분류용 데이터 세트 준비
이번에는 위스콘신 유방암 데이터 세트를 사용합니다. 유방암 데이터 세트에는 유방암 세포의 특성 10개에 대해 평균, 표준 오차, 최대 이상치가 기록되어 있습니다. 이번에 해결할 문제는 데이터 샘플이 악성 종양인지 정상 종양인지 분류하는 이진 분류 문제입니다.
이진 분류 문제에서는 해결하려 하는 문제를 양성 샘플(positive sample)로 분류합니다. 우리가 찾으려고 하는 것은 악성 종양이므로, 악성 종양을 양성 샘플로 분류할 것입니다.
1. load_breast_cancer() 함수 호출
함수를 호출하여 데이터를 불러옵니다.
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
2. 입력 데이터 확인
먼저, 불러온 데이터의 크기를 보겠습니다.
print(cancer.data.shape, cancer.target.shape)
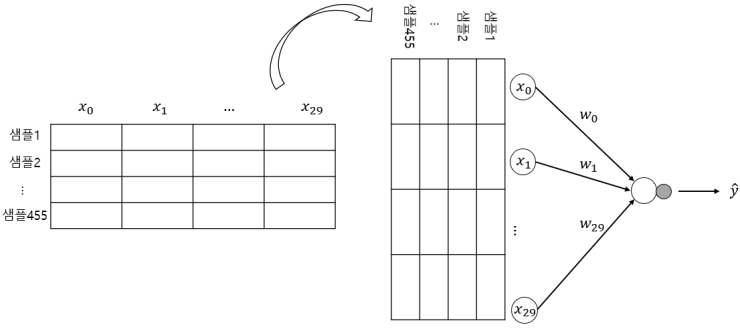
569개의 샘플이 있고, 각 샘플 당 특성은 30개 입니다. 처음 3개의 샘플을 확인해보겠습니다.
cancer.data[:3]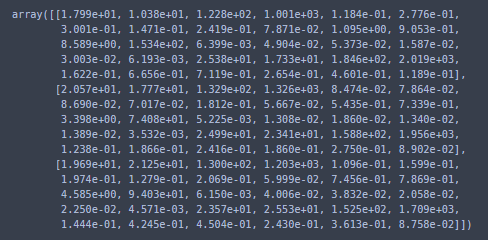
3. 박스 플롯으로 특성 확인하기
30개의 특성을 산점도로 나타내기는 어려우므로, 박스 플롯을 사용하여 데이터를 확인해보겠습니다.
%matplotlib inline
import matplotlib.pyplot as plt
plt.boxplot(cancer.data)
plt.xlabel('feature')
plt.ylabel('value')
plt.show()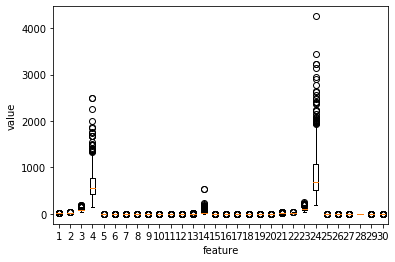
4. 눈에 띄는 특성 확인하기
그래프를 보니 4, 14, 24번째 데이터가 다른 데이터들에 비해 값의 분포가 크다는 것을 알 수 있습니다. 이 특성들이 무엇인지 확인해봅니다.
cancer.feature_names[[3, 13, 23]]
각 특성의 이름을 보니, 모두 넓이에 관한 특성임을 알 수 있습니다.
5. 타깃 데이터 확인하기
이번 문제는 이진 분류이므로, 타깃 데이터는 0과 1밖에 없습니다. 0은 음성 클래스, 1은 양성 클래스를 의미합니다.

import numpy as np
np.unique(cancer.target, return_counts=True)
확인 결과, 음성 클래스가 212개, 양성 클래스가 357개임을 알 수 있습니다.
6. 훈련 데이터 저장하기
앞으로 사용할 위 데이터들을 변수에 저장합니다.
x = cancer.data
y = cancer.target
로지스틱 회귀를 위한 뉴런
훈련된 모델의 실전 성능을 일반화 성능(generalization performance)라고 합니다. 훈련된 모델을사용하여 어떤 데이터에 대한 예측을 할 때, 훈련 시 사용했던 데이터를 그대로 다시 사용하면 예측 결과는 당연히 좋게 나올 것입니다. 이는 학생에게 시험 예상 문제를 주고 공부를 시킨 다음, 시험에 그 예상 문제를 똑같이 내는 경우에 비유할 수 있습니다.
선생님들은 보통 학생에게 시험 문제를 낼 때, 예상 문제에서 약간 수정한 문제를 내지, 전혀 예상치 못한 문제를 내는 경우는 별로 없습니다. 이런 경우에는 학생들이 거의 그 문제를 풀지 못합니다. 머신러닝도 이와 비슷합니다. 예상 문제를 통해 훈련을 하고, 예상 문제와 약간 다른 문제를 받아 이에 대한 예측을 하고, 전혀 다른 문제가 들어오면 이에 대한 결과는 대부분 좋지 않은 결과가 나옵니다.
우리에게 데이터가 주어졌을 때, 모델을 적절하게 평가하기 위한 방법은 데이터 세트를 훈련 세트(training set)와 테스트 세트(test set)로 나누는 것입니다.
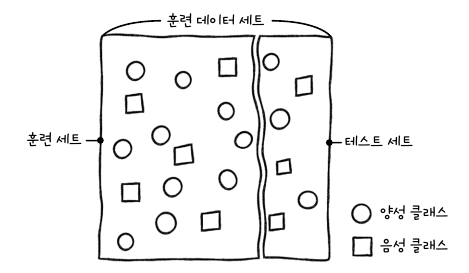
데이터를 나눌 때는 다음의 규칙이 있습니다.
- 테스트 세트보다 훈련 세트가 더 많아야합니다
- 훈련 세트를 나누기 전에, 클래스들이 어느 한쪽에 쏠리지 않게 골고루 섞어야합니다.
훈련 데이터를 나눌 때, 어느 한 쪽에 특정 클래스가 많이 몰리게 되면 모델이 데이터에 있는 패턴을 제대로 학습하지 못하거나 성능을 잘못 측정할 수도 있습니다.
이제, 사이킷런을 사용하여 데이터 세트를 나눠보도록 하겠습니다.
1. train_test_split() 함수로 데이터 세트 나누기
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, stratify=y, test_size=0.2, random_state=42)
stratify : 해당 매개변수 값에 들어가는 클래스의 비율을 유지해줍니다. 우리 데이터에서 각 클래스의 비율은 212:357이므로, 이를 유지해주도록 하는 매개변수입니다. 만약 변수 이름이 target이라면 y 대신 target을 넣어줘야 합니다.
test_size : 훈련 세트와 테스트 세트의 비율을 정해줍니다. 기본값은 0.25입니다.
random_state : 난수를 설정합니다. 훈련을 재연할 때, 똑같은 결과를 볼 수 있도록 설정해주는 파라미터입니다. 실전에서는 필요 없는 파라미터입니다.
2. 결과 확인하기
print(x_train.shape, x_test.shape)
np.unique(y_train, return_counts=True)
line 1.에서는 훈련 데이터와 트레이닝 데이터로 잘 나뉘었는지 확인합니다. 455:114 = 약 4:1 비율로 잘 나뉜 것을 확인할 수 있습니다.
line 2.에서는 훈련 데이터 중에서 클래스의 비율이 잘 유지되었는지 확인합니다. 170:285 = 약 212:357비율로 잘 나뉜 것을 확인할 수 있습니다.
로지스틱 회귀 구현하기
LogisticNeuron 클래스의 전체 코드는 다음과 같습니다.
class LogisticNeuron:
def __init__(self):
self.w = None
self.b = None
def forpass(self, x):
z = np.sum(x*self.w) + self.b
return z
def backprop(self, x, err):
w_grad = -err*x
b_grad = -err*1
return w_grad, b_grad
def activation(self, z):
a = 1 / (1 + np.exp(-z))
return a
def fit(self, x, y, epochs=100):
self.w = np.ones(x.shape[1])
self.b = 0
for _ in range(epochs):
for x_i, y_i in zip(x, y):
z = self.forpass(x_i)
a = self.activation(z)
err = y_i - a
w_grad, b_grad = self.backprop(x_i, err)
self.w -= w_grad
self.b -= b_grad
def predict(self, x):
z = [self.forpass(x_i) for x_i in x]
a = self.activation(np.array(z))
return a > 0.5
1. __init__, forpass, backprop 메서드 작성하기
class LogisticNeuron:
def __init__(self):
self.w = None
self.b = None
def forpass(self, x):
z = np.sum(x*self.w) + self.b
return z
def backprop(self, x, err):
w_grad = -err*x
b_grad = -err*1
return w_grad, b_grad
이전 포스트의 선형 회귀와 달라진 부분은 다음과 같습니다.
__init__ : 가중치를 미리 초기화 하지 않습니다. 입력 데이터의 크기에 맞게, 나중에 훈련하기 직전에 결정합니다.
forpass : 특성 개수가 많으므로 점곱을 사용하여 계산합니다.
2. activation 메서드 작성하기
def activation(self, z):
a = 1 / (1 + np.exp(-z))
return a로지스틱 회귀에서 활성화 함수는 시그모이드 함수를 사용합니다.
3. fit 메서드 작성하기
def fit(self, x, y, epochs=100):
self.w = np.ones(x.shape[1])
self.b = 0
for _ in range(epochs):
for x_i, y_i in zip(x, y):
z = self.forpass(x_i)
a = self.activation(z)
err = y_i - a
w_grad, b_grad = self.backprop(x_i, err)
self.w -= w_grad
self.b -= b_grad
가중치와 절편을 초기화합니다. 가중치는 입력 데이터의 크기에 맞게 초기화합니다. 오차는 타깃값과 활성화 함수 출력의 차이를 계산합니다.
4. predict 메서드 작성하기
def predict(self, x):
z = [self.forpass(x_i) for x_i in x]
a = self.activation(np.array(z))
return a > 0.5
입력값은 2차원 배열이라고 가정합니다. 모델에 저장된 가중치와 절편 값으로 입력 데이터의 결과를 예측합니다.
5. 모델을 훈련하고, 정확도 평가하기
neuron = LogisticNeuron()
neuron.fit(x_train, y_train)
np.mean(neuron.predict(x_test) == y_test)
실행 결과, 정확도는 약 82%입니다.
로지스틱 회귀 뉴런으로 단일층 신경망 만들기
일반적으로, 신경망은 다음 그림과 같이 표현합니다.
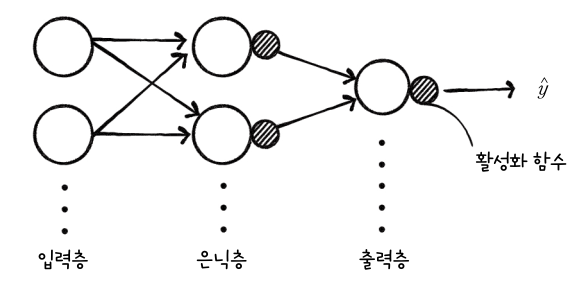
가장 왼쪽은 입력층(input layer), 가운데 층들은 은닉층(hidden layer), 오른쪽은 출력층(output layer)라고 합니다. 각 뉴런의 오른쪽에 작은 원으로 붙은 활성화 함수는 각 층의 한 부분으로 간주합니다.
이전에 우리가 구현한 로지스틱 회귀는 은닉층이 없는 형태입니다. 이렇게 입력층과 출력층만 가지는 신경망을 단일층 신경망이라고 합니다. 이를 그림으로 나타내면 다음과 같습니다.
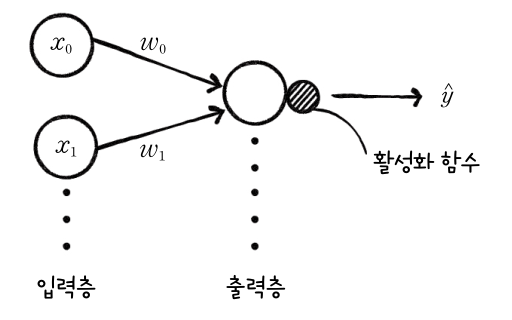
우리가 구현한 로지스틱 회귀를 위 그림처럼 나타내면 다음과 같습니다.
여러 가지 경사 하강법
지금까지 사용한 경사 하강법은 샘플 1개에 대한 그래이디언트를 계산했으며, 이 방법을 확률적 경사 하강법(stochastic gradient descent) 이라고 합니다.

전체 훈련 세트를 사용하여 한 번에 그래이디언트를 계산하는 방법을 배치 경사 하강법(batch gradient descent) 이라고 합니다.

일부 훈련 세트를 사용하여 그래이디언트를 계산하는 방법을 미니 배치 경사 하강법(mini-batch gradient descent)이라고 합니다.

확률적 경사하강법은 샘플 데이터 1개씩 그래이디언트를 계산하여 가중치를 업데이트 하므로 계산 속도가 빠른 대신 가중치가 최적값에 수렴하는 과정이 불안정하지만, 배치 경사 하강법은 전체 훈련 데이터를 사용하여 한 번에 그래이디언트를 계산하므로 가중치가 최적값에 수렴하는 과정은 안정하지만, 계산 속도가 느립니다. 이 둘을 적절히 섞은 것이 미니 배치 경사 하강법입니다.
위 경사 하강법들은 에포크마다 훈련 세트의 샘플 순서를 섞어 가중치의 최적값을 계산해야 합니다. 즉, 훈련 데이터를 무작위로 선택해야 하는 것인데, 이 방법을 사용해야 가중치 최적값의 탐색 과정이 다양해져 최적값을 제대로 찾을 수 있기 때문입니다.
단일층 신경망 구현하기
몇 가지 유용한 기능을 추가하기 위해 이전에 사용했던 LogisticNeuron 클래스를 수정할 것입니다. 해당 부분을 복사해서 사용하세요. 전체 코드는 다음과 같습니다.
class SingleLayer:
def __init__(self):
self.w = None
self.b = None
self.losses = []
def forpass(self, x):
z = np.sum(x*self.w) + self.b
return z
def backprop(self, x, err):
w_grad = -err*x
b_grad = -err*1
return w_grad, b_grad
def activation(self, z):
a = 1 / (1 + np.exp(-z))
return a
def fit(self, x, y, epochs=100):
self.w = np.ones(x.shape[1])
self.b = 0
for _ in range(epochs):
loss = 0
indexes = np.random.permutation(np.arange(len(x)))
for i in indexes:
z = self.forpass(x[i])
a = self.activation(z)
err = y[i] - a
w_grad, b_grad = self.backprop(x[i], err)
self.w -= w_grad
self.b -= b_grad
a = np.clip(a, 1e-10, 1-1e-10)
loss += -(y[i]*np.log(a) + (1 - y[i])*np.log(1 - a))
self.losses.append(loss/len(y))
def predict(self, x):
z = [self.forpass(x_i) for x_i in x]
return np.array(z) > 0
def score(self, x, y):
return np.mean(self.predict(x) == y)
손실 함수의 결과를 저장하고, 샘플 순서 섞기
__init__() 메서드에 손실 함수의 결과를 저장할 self.losses 변수를 만듭니다.
def __init__(self):
self.w = None
self.b = None
self.losses = []
샘플마다 손실 함수를 계산하고, 에포크를 반복할 때마다 샘플의 평균 손실을 계산하여 self.losses 변수에 저장합니다. self.activation() 메서드로 계산한 값은 $\a$가 0에 가까워지면 np.log()의 값은 음의 무한대가 되고, 1에 가까워지면 np.log()함수의 값이 0이 됩니다. 손실값이 무한해지면 정확한 계산을 할 수 없기 때문에 np.clip()함수를 사용하여 $a$의 값을 제한합니다.
또한, 에포크마다 np.random.permutation()함수를 사용하여 샘플 순서를 섞습니다. 이 방법은 직접적으로 샘플을 섞는 것은 아니고, 배열의 인덱스를 섞어 해당 인덱스의 샘플을 훈련에 사용하는 방법입니다. 직접 배열의 요소를 섞는 방법보다는 인덱스만 섞어서 해당 배열을 참조하는 것이 시간 복잡도 측면에서 훨씬 효율적이기 때문입니다.
def fit(self, x, y, epochs=100):
self.w = np.ones(x.shape[1])
self.b = 0
for _ in range(epochs):
loss = 0
indexes = np.random.permutation(np.arange(len(x)))
for i in indexes:
z = self.forpass(x[i])
a = self.activation(z)
err = y[i] - a
w_grad, b_grad = self.backprop(x[i], err)
self.w -= w_grad
self.b -= b_grad
a = np.clip(a, 1e-10, 1-1e-10)
loss += -(y[i]*np.log(a) + (1 - y[i])*np.log(1 - a))
self.losses.append(loss/len(y))
score() 메서드 추가하기
정확도를 계산해주는 score() 메서드를 추가하고, 기존의 predict() 메서드도 수정합니다. 시그모이드 함수의 출력은 0~1사이이고, 0.5를 기준으로 양성과 음성을 나눕니다. 그런데 이는 $z$의 값을 0을 기준으로 나누는 것과 같은 결과입니다. $z$가 0보다 크면 시그모이드 함수의 값은 0.5보다 크고, 0보다 작으면 시그모이드 함수의 값은 0.5보다 작기 때문입니다. 따라서 시그모이드 함수를 굳이 사용하지 않고, $z$값만을 사용해도 됩니다.
def predict(self, x):
z = [self.forpass(x_i) for x_i in x]
return np.array(z) > 0
def score(self, x, y):
return np.mean(self.predict(x) == y)
단일층 신경망 훈련하기
위에서 구현한 코드를 갖고, 이전과 같이 이 신경망을 훈련해봅니다
layer = SingleLayer()
layer.fit(x_train, y_train)
layer.score(x_test, y_test)
기존의 LogisticNeuron과 마찬가지로 100개의 에포크만 사용했는데 정확도가 약 0.82에서 약 0.92로 향상되었습니다. 이는 훈련 샘플을 무작위로 섞어서 손실 함수의 값을 줄였기 때문입니다.
손실 함수 누적값 확인하기
plt.plot(layer.losses)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
사이킷런으로 로지스틱 회귀 구현해보기
사이킷런의 SGD Classifier 클래스는 경사 하강법이 구현되어있습니다. 이 클래스는 로지스틱 회귀 외에도 여러 문제에 경사 하강법을 적용할 수 있습니다.
from sklearn.linear_model import SGDClassifier
sgd = SGDClassifier(loss='log', max_iter=100, tol=1e-3, random_state=42)
sgd.fit(x_train, y_train)
sgd.score(x_test, y_test)
loss : 손실 함수를 지정해줍니다. 'log'는 로지스틱 손실 함수를 의미합니다.
tol : tolerance를 설정합니다. 이 값만큼 손실 함수의 값이 감소하지 않으면 반복을 중단합니다.
다음 코드로 예측 결과를 확인해봅니다.
print(sgd.predict(x_test[0:10]))
print(y_test[0:10])
위 트레이닝 결과로는 처음 11개의 샘플 중 4, 6번째 샘플의 예측이 틀린 것을 확인할 수 있습니다.