[Do it!]7. 텍스트 분류하기 - 순환 신경망
이 포스트는 Do it! 정직하게 코딩하며 배우는 딥러닝 입문 pp.280~317을 참고하였습니다.
순차 데이터와 순환 신경망
순차 데이터
지금까지 사용했던 데이터는 각 샘플이 독립적이라고 가정했습니다. 따라서 에포크마다 전체 샘플을 무작위로 섞을 수 있었습니다.
하지만, 우리가 배울 데이터 중에서는 독립적이지 않은 샘플이 많이 있습니다. 예를 들면, 날씨 정보나 텍스트 같은 경우입니다. 예를 들어 날씨 데이터의 경우, 오후 3시의 온도가 20도였다면, 오후 12시~2시 또는 오후 4시~6시의 온도는 20도에서 그렇게 크게 벗어나지 않을 것이라는 것을 압니다. 또한, 오후 4시~6시는 오후 3시의 온도보다 더 내려갈 것이라는 것 또한 압니다. 즉, 어떤 한 데이터를 알면 다른 데이터에 대한 정보도 얻을 수 있기 때문에, 각 데이터들이 독립적이지 않습니다.
위의 예시와 같이 일정 시간 간격으로 배치된 데이터를 시계열(time series) 데이터라고 합니다. 시계열 데이터를 포함해서 샘플에 순서가 있는 데이터를 순차 데이터(sequential data)라고 합니다. 텍스트 데이터는 대표적인 순차 데이터입니다. 텍스트 데이터 또한 각 샘플이 독립적이지 않습니다. 우리가 사용하는 말에는 문법이 있고, 이 문법에 따라 단어가 배열됩니다. 예를 들어, "I like fruits" 즉, (주어 > 동사 > 목적어) 의 순서로 배열이 되어있는 문장을 생각해보겠습니다. 주어로 사용되는 단어가 나오면, 그 다음으로는 동사로 사용되는 단어가 나올것임을 알 수 있습니다. 즉, 다른 샘플에 대한 정보를 알 수 있으므로, 각 샘플이 독립적이지 않습니다.
순차 데이터를 처리하는 모델에서, 데이터를 처리하는 각 단계를 타임 스텝이라고 합니다. 위의 예시는 데이터의 처리 단위가 단어인 경우입니다. 따라서, 총 타임 스텝은 3입니다. 만약 데이터의 처리 단위가 글자라면 총 타임 스텝은 13입니다(띄어쓰기를 포함합니다).
이렇게 순차 데이터는 "이전 샘플이 무엇이었는가?"가 매우 중요합니다. 하지만, 우리가 지금까지 구현했던 신경망은 이전 샘플에 대한 정보를 유지하지 않습니다. 따라서, 다른 구조의 신경망이 필요합니다.
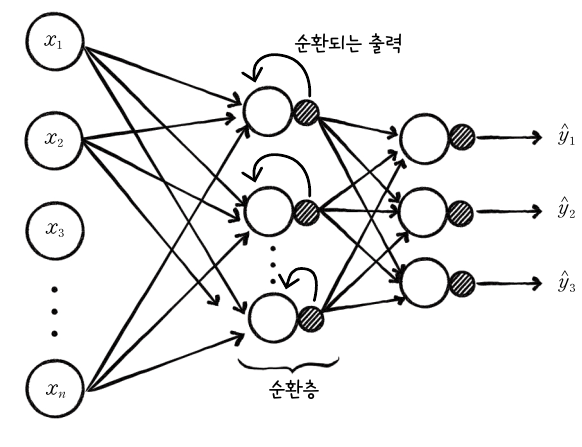
순환 신경망은 위 그림과 같이 뉴런의 출력이 순환되는 신경망을 말합니다. 지금까지 봤던 신경망과 다르게, 은닉층의 출력이 다시 은닉층의 입력으로 사용되는 구조를 갖고있습니다. 이를 순환 구조라고 하며, 이 구조가 있는 층을 순환층이라고 합니다.
은닉층에서 순환된 출력은 다음 입력을 처리할 때 현재 입력과 같이 사용됩니다. 즉, 이전 샘플의 정보를 현재 샘플을 처리할 때 참조할 수 있습니다. 즉, 이전 샘플의 데이터를 고려하는 것입니다.
순환 신경망에서는 층이나 뉴런을 셀(cell)이라고 합니다. 순환 신경망에서는 셀의 출력을 은닉 상태(hidden state)라고 합니다. 다음은 입력을 $x$, 출력을 $h$라고 표시해서 나타낸 순환층의 그림입니다.

순환 신경망은 이전의 출력을 사용한다고 했습니다. 위 셀에서, 이전 출력을 사용하기 위한 이전 타임 스텝의 은닉 상태 $h_p$를 추가합니다.

순환층의 셀에서 이루어지는 정방향 계산은 다음과 같습니다.

지금까지는 뉴런 하나에 학습되는 파라미터가 입력과 곱하는 가중치, 절편 이렇게 2개였는데 이제는 셀 하나에 입력과 곱하는 가중치, 절편, 이전 출력과 곱하는 가중치 이렇게 3개입니다. 또한, 활성화 함수로는 쌍곡선 탄젠트 함수 tanh를 사용합니다.
순환 신경망의 정방향 계산

위 그림은 이진 분류를 위해 하나의 순환층과 입력층, 출력층을 가진 단순한 신경망을 나타낸 것입니다.
순환층의 정방향 계산에서 선형 출력 $\mathbf{Z}_1$은 이전의 그림에서 나타냈듯이 $\mathbf{XW}_{1x} + \mathbf{H}_p\mathbf{W}_{1h}+\pmb{b}_1$이고, 활성화 함수로는 쌍곡선 탄젠트 함수를 사용하므로, 순환층의 출력은 $\mathbf{H} = \tanh(\mathbf{Z}_1)$입니다.
출력층의 정방향 계산에서 선형 출력은 위의 그림에서 볼 수 있듯이 $\mathbf{Z}_2 = \mathbf{HW}_2+\pmb{b}_2$이고, 활성화 함수로는 시그모이드 함수를 사용하므로, 출력 $\mathbf{A}_2 = \mathrm{sigmoid}(\mathbf{Z}_2)$입니다.
이제 정방향 계산에 필요한 입력과 가중치의 구조를 알아보겠습니다. 샘플의 수가 $m$개이고 특성의 수가 $n_f$인 입력 데이터 $\mathbf{X}$를 사용한다고 가정해보겠습니다. 일단 지금은 타임 스텝 하나에 대한 구조만 알아보겠습니다.

$mathbf{X}$와 곱해지는 가중치 $\mathbf{W}_{1x}$의 크기는 $(n_f, n_c)$입니다. $n_c$는 순환층에 있는 뉴런의 개수입니다.

따라서 $\mathbf{X}$와 $\mathbf{W}_{1x}$를 점곱하면 그 결과의 크기는 $(m, n_c)$입니다. $\mathbf{XW}_{1x}$의 크기가 $(m, n_c)$이므로 $\mathbf{Z}_1, \mathbf{H}, \mathbf{H}_p$의 크기 모두 $(m, n_c)$입니다. 따라서 $\mathbf{H}_p$에 가중치 $\mathbf{W}_{1h}$가 곱해진 결과도 $(m, n_c)$크기를 가져야 하므로, $\mathbf{W}_{1h}$의 크기는 $(n_c, n_c)$임을 알 수 있습니다.
이번엔 출력층을 보겠습니다. 출력층 결과의 크기는 $(m, n_classes)$가 되어야 합니다. 그리고 출력층의 입력으로 사용되는 $\mathbf{H}$의 크기는 $(m, n_c)$네요. 따라서 이와 곱해지는 가중치인 $\mathbf{W}_2$의 크기는 $(n_c, n_classes)$입니다. 이에 따라 선형 출력과 활성화 출력인 $\mathbf{Z}_2, \mathbf{A}_2$의 크기는 $(m, n_classes)$입니다.
절편의 경우, 각 층의 뉴런마다 하나씩의 절편이 필요하므로 $\pmb{b}_1$의 크기는 $(n_c, )$이고, $\pmb{b}_2$의 크기는 $(n_classes, )$ 입니다.
순환 신경망의 역방향 계산
가중치 $\mathbf{W}_2$에 대한 손실 함수의 도함수 구하기

이진 분류의 문제이므로, 손실 함수는 로지스틱 손실 함수를 사용합니다. 이전에 로지스틱 손실 함수를 미분한 것과 같은 방법으로 미분을 진행합니다.
$\frac{\partial \mathbf{L}}{\partial \mathbf{W}_2} = \frac{\partial \mathbf{L}}{\partial\mathbf{Z}_2}\frac{\partial \mathbf{Z}_2}{\partial\mathbf{W}_2} = \mathbf{H}^\mathrm{T}(-(\mathbf{Y-A}_2))$
$\frac{\partial \mathbf{L}}{\partial \pmb{b}_2} = \frac{\partial \mathbf{L}}{\partial\mathbf{Z}_2}\frac{\partial \mathbf{Z}_2}{\partial\pmb{b}_2} = \mathbf{1}^\mathrm{T}(-(\mathbf{Y-A}_2))$
가중치 $\mathbf{W}_{1h}$에 대한 손실 함수의 도함수 구하기

이전과 같은 방식으로, 화살표를 따라 연쇄 법칙을 적용하면 다음과 같습니다.
$\frac{\partial \mathbf{L}}{\partial \mathbf{W}_{1h}} = \frac{\partial \mathbf{L}}{\partial\mathbf{Z}_2}\frac{\partial \mathbf{Z}_2}{\partial\mathbf{H}}\frac{\partial \mathbf{H}}{\partial\mathbf{Z}_1}\frac{\partial \mathbf{Z}_1}{\partial\mathbf{W}_{1h}}$
$\mathbf{Z}_2$를 $\mathbf{H}$에 대해 미분하기
$\frac{\partial \mathbf{Z}_2}{\partial \mathbf{H}} =\frac{\partial}{\partial \mathbf{H}}(\mathbf{HW}_2+\pmb{b}_2)=\mathbf{W}_2$
$\mathbf{H}$를 $\mathbf{Z}_1$에 대해 미분하기
$\mathbf{H} = \tanh(\mathbf{Z}_1)$이므로, 이를 미분하기 위해서는 $\tanh$의 도함수를 구해야 합니다. $\tanh(x)$는 다음과 같이 정의됩니다.

위 식을 미분하면 다음과 같습니다.

따라서,

입니다.
$\mathbf{Z}_1$을 $\mathbf{W}_{1h}$에 대해 미분하기
이전과 같은 방법으로 미분해보기 위해 식을 전개해보겠습니다.

하지만, 위와 같은 결과가 나오기 위해서는 $\mathbf{W}_{1h}$를 제외하고 나머지는 모두 상수여야 가능한데, 이전 타임 스텝의 은닉 상태 $\mathbf{H}_p$도 $\mathbf{W}_{1h}$에 대한 식이므로 위와 같이 미분하는 것은 불가능합니다. 좀 더 자세히 알아보기 위해 그림을 확장해보겠습니다.

위 그림을 보면, 이전 타임 스텝의 은닉 상태 $\mathbf{H}_p$도 아래의 식과 같이 $\mathbf{W}_{1h}$에 관계된 식이라는 것을 알 수 있습니다.

정리하자면, $\mathbf{H}_p$는 이전 타임 스텝 입력인 $\mathbf{X}_p$와 두 타임 스텝 이전의 은닉 상태 $\mathbf{H}_{pp}$를 사용하여 계산합니다. 여기서 중요한 점은, 타임 스텝마다 가중치 $\mathbf{W}_{1x}, \mathbf{W}_{1h}, \pmb{b}_1$은 동일하다는 것입니다. 이 값들은 훈련 데이터에 있는 시퀀스를 차례대로 모두 진행한 후, 마지막에 업데이트됩니다. 이제, $\mathbf{Z}_1$를 다시 미분해보겠습니다.

이제 $mathbf{H}_p$를 $\mathbf{W}_{1h}$에 대해 미분하기 위해 다시 역방향으로 진행해봅니다.

위 그림에서 연쇄법칙을 적용해보면 아래와 같은 식을 유도할 수 있습니다.

방금 전에 $\tanh$를 미분해봤기 때문에 $\frac{\partial \mathbf{H}_p}{\partial \mathbf{Z}_{1p}}$를 다음과 같이 나타낼 수 있습니다.

이제 $\mathbf{Z}_{1p}$를 미분해야하는데, 이 값 또한 $\mathbf{W}_{1h}$에 대한 값입니다. 따라서 앞의 과정을 반복하면, 아래와 같은 값을 얻을 수 있습니다.

위 식을 보니 $\frac{\partial \mathbf{Z}_{1pp}}{\partial \mathbf{W}_{1h}}$가 또 있네요. 이러면 계속 위와 같은 방식의 미분이 반복됩니다. 이 과정은 순환 신경망에 주입된 모든 타임 스텝을 거슬러 올라갈 때까지 계속됩니다. 이를 시간을 거슬러 역전파(Backpropagation through time, BPTT)라고 합니다.
여기서 중요한 점은, 순환 신경망의 역전파를 구하기 위해서는 각 타임 스텝마다 셀의 출력 $\mathbf{H}_p, \mathbf{H}_{pp}, \mathbf{H}_{ppp}, \dots$를 모두 기록해서 가지고 있어야 합니다.
따라서 위의 식을 계속 이어나가면 아래와 같은 식을 구할 수 있습니다.

$\mathbf{Z}_1$을 $\mathbf{W}_{1x}$에 대해 미분하기

위 식을 미분하려고 보니, 또 $\mathbf{H}_p$가 $\mathbf{W}_{1x}$에 대한 식입니다. 따라서 이전의 방법을 다시 적용해야 할 것 같네요.

반복되는 부분이 보입니다. 한 타임 스텝 더 전개해보겠습니다.

위 식의 괄호를 풀어 정리해보면, 앞에서 보았던 패턴이 다시 보이는 것을 볼 수 있습니다.

$\mathbf{Z}_1$을 $\pmb{b}_1$에 대해 미분하기
이전과 같은 방법으로 구합니다.

이제 필요한 모든 것을 구했습니다. 이전에 구현했던 신경망에서는 은닉층 직전까지 전파된 그래이디언트를 err_to_hidden이라고 해서 코드를 구현했는데, 순환 신경망에서는 오차 함수가 순환 셀 직전까지 전파된 $\frac{\partial \mathbf{L}}{\partial \mathbf{Z}_1}를 err_to_cell 이라고 표현해서 코드를 구현할 것입니다.
순환 신경망을 만들고 텍스트 분류하기
데이터 준비하기
이번에 구현해볼 신경망은 영화 리뷰 데이터를 보고, 긍정인지 부정인지 분류하는 이진 분류를 위한 신경망입니다.
IMDB 데이터 세트를 사용할 것이며, 이 데이터 세트는 리뷰에 포함된 8만개 이상의 단어를 고유한 정수로 미리 바꾸어 놓은 상태입니다. 예를 들어, real = 100, impressive = 3215 이런식입니다.
데이터 불러오기
import numpy as np
from tensorflow.keras.datasets import imdb
(x_train_all, y_train_all), (x_test, y_test) = imdb.load_data(skip_top=20, num_words=100)
print(x_train_all.shape, y_train_all.shape)skip_top에는 가장 많이 등장한 단어들 중 건너 뛸 단어의 수를 의미합니다. 예를 들어 a, the, is같은 단어들은 많이 등장하지만 분석에는 별로 도움이 되지 않으므로 건너뜁니다. num_words는 훈련에 사용할 단어의 수를 지정합니다.

샘플 확인하기
print(x_train_all[0])
샘플을 보면 정수들이 보이는데, 이 수들은 영단어를 1:1 대응시킨 것으로, BoW(Bag of Word) 또는 어휘 사전이라고 합니다. 여기서 2가 많이 보이는데, 아까 훈련에 사용하기로 한 num_words의 범위에 속하지 않는 단어들이 여기서는 2로 나타나게 됩니다. 따라서, 이 단어들은 사용하지 않을 것이므로 다음과 같이 2를 제거합니다.
for i in range(len(x_train_all)):
x_train_all[i] = [w for w in x_train_all[i] if w > 2]
print(x_train_all[0])
어휘 사전 내려받기
위 정수들이 무슨 단어를 뜻하는지 확인하기 위해 어휘 사전을 내려받고, 확인해봅니다.
word_to_index = imdb.get_word_index()
word_to_index['movie']
훈련 세트의 정수를 영단어로 변환하기
훈련 세트에 있는 값들은 3 이상부터 영단어를 의미합니다. 따라서 그 값에서 3을 빼고, 이를 어휘 사전의 인덱스로 사용해야 합니다. 아까 확인했던 훈련 데이터를 영단어로 변환해서 확인해보겠습니다.
index_to_word = {word_to_index[k]: k for k in word_to_index}
for w in x_train_all[0]:
print(index_to_word[w-3], end=' ')
데이터의 길이 확인하기
print(len(x_train_all[0]), len(x_train_all[1]))데이터를 보니 길이가 다릅니다. 영화 리뷰라고 했으니 길이가 같은 경우는 거의 없을것입니다. 샘플의 길이가 다르면 훈련을 제대로 시킬 수 없습니다. 이에 대한 해결법은 잠시 후 설명합니다.
타깃 데이터 확인하기
print(y_train_all[:10])
긍정 데이터는 1, 부정 데이터는 0으로 나타냅니다.
검증 세트 준비하기
np.random.seed(42)
random_index = np.random.permutation(25000)
x_train = x_train_all[random_index[:20000]]
y_train = y_train_all[random_index[:20000]]
x_val = x_train_all[random_index[20000:]]
y_val = y_train_all[random_index[20000:]]리뷰 데이터는 데이터의 길이가 달라 넘파이 배열이 아닌 파이썬 리스트이므로, 사이킷런으로 자동으로 데이터를 나눌 수 없습니다. 따라서 이렇게 직접 훈련 세트와 검증 세트로 나눠줘야 합니다.
샘플의 길이 맞추기
아까 샘플의 길이가 다르면 훈련이 제대로 되지 않는다고 했습니다. 여기서는 일정 길이를 지정하고, 데이터의 길이가 이 길이보다 크면 데이터를 잘라버리고 이 길이보다 작으면 0으로 채웁니다. 예를 들어 이 길이를 7로 지정하는 경우, 다음과 같습니다.

여기서 중요한 점은, 데이터의 끝 부분이 아닌 시작 부분에 0으로 채운다는 것입니다. 데이터의 끝 부분에 0을 추가하면 이후 샘플이 순환 신경망에 주입될 때 0이 마지막에 주입되므로 모델의 성능이 좋지 않게 됩니다.
텐서플로를 사용하여 샘플의 길이 맞추기
from tensorflow.keras.preprocessing import sequence
maxlen = 100
x_train_seq = sequence.pad_sequences(x_train, maxlen=maxlen)
x_val_seq = sequence.pad_sequences(x_val, maxlen=maxlen)
print(x_train_seq.shape, x_val_seq.shape)
print(x_train_seq[0])
원-핫 인코딩하기
from tensorflow.keras.utils import to_categorical
x_train_onehot = to_categorical(x_train_seq)
x_val_onehot = to_categorical(x_val_seq)
print(x_train_onehot.shape)
여기서 문제는, 이렇게 많은 데이터를 100개의 레이블로 원-핫 인코딩을 하면 데이터 용량이 엄청나게 커진다는 문제가 있습니다.
print(x_train_onehot.nbytes)
순환 신경망 클래스 구현하기
전체 코드는 다음과 같습니다.
import tensorflow as tf
class RecurrentNetwork:
def __init__(self, n_cells=10, batch_size=32, learning_rate=0.1):
self.n_cells = n_cells
self.batch_size = batch_size
self.w1h = None
self.w1x = None
self.b1 = None
self.w2 = None
self.b2 = None
self.h = None
self.losses = []
self.val_losses = []
self.lr = learning_rate
def forpass(self, x):
self.h = [np.zeros((x.shape[0], self.n_cells))]
seq = np.swapaxes(x, 0, 1)
for x in seq:
z1 = np.dot(x, self.w1x) + np.dot(self.h[-1], self.w1h) + self.b1
h = np.tanh(z1)
self.h.append(h)
z2 = np.dot(h, self.w2) + self.b2
return z2
def backprop(self, x, err):
m = len(x)
w2_grad = np.dot(self.h[-1].T, -err) / m
b2_grad = np.sum(-err) / m
seq = np.swapaxes(x, 0, 1)
w1h_grad = w1x_grad = b1_grad = 0
err_to_cell = np.dot(-err, self.w2.T) * (1 - self.h[-1]**2)
for x, h in zip(seq[::-1][:10], self.h[:-1][::-1][:10]):
w1h_grad += np.dot(h.T, err_to_cell)
w1x_grad += np.dot(x.T, err_to_cell)
b1_grad += np.sum(err_to_cell, axis=0)
err_to_cell = np.dot(err_to_cell, self.w1h) * (1 - h**2)
w1h_grad /= m
w1x_grad /= m
b1_grad /= m
return w1h_grad, w1x_grad, b1_grad, w2_grad, b2_grad
def sigmoid(self, z):
a = 1 / (1 + np.exp(-z))
return a
def init_weights(self, n_features, n_classes):
orth_init = tf.initializers.Orthogonal()
glorot_init = tf.initializers.GlorotUniform()
self.w1h = orth_init((self.n_cells, self.n_cells)).numpy()
self.w1x = glorot_init((n_features, self.n_cells)).numpy()
self.b1 = np.zeros(self.n_cells)
self.w2 = glorot_init((self.n_cells, n_classes)).numpy()
self.b2 = np.zeros(n_classes)
def fit(self, x, y, epochs=100, x_val=None, y_val=None):
y = y.reshape(-1, 1)
y_val = y_val.reshape(-1, 1)
np.random.seed(42)
self.init_weights(x.shape[2], y.shape[1])
for i in range(epochs):
print('epoch : ', i, end=' ')
batch_losses = []
for x_batch, y_batch in self.gen_batch(x, y):
print('.', end='')
a = self.training(x_batch, y_batch)
a = np.clip(a, 1e-10, 1-1e-10)
loss = np.mean(-(y_batch*np.log(a) + (1-y_batch)*np.log(1-a)))
batch_losses.append(loss)
print()
self.losses.append(np.mean(batch_losses))
self.update_val_loss(x_val, y_val)
def gen_batch(self, x, y):
length = len(x)
bins = length // self.batch_size
if length % self.batch_size:
bins += 1
indexes = np.random.permutation(np.arange(len(x)))
x = x[indexes]
y = y[indexes]
for i in range(bins):
start = self.batch_size*i
end = self.batch_size*(i + 1)
yield x[start:end], y[start:end]
def training(self, x, y):
m = len(x)
z = self.forpass(x)
a = self.sigmoid(z)
err = y - a
w1h_grad, w1x_grad, b1_grad, w2_grad, b2_grad = self.backprop(x, err)
self.w1h -= self.lr*w1h_grad
self.w1x -= self.lr*w1x_grad
self.b1 -= self.lr*b1_grad
self.w2 -= self.lr*w2_grad
self.b2 -= self.lr*b2_grad
return a
def predict(self, x):
z = self.forpass(x)
return z > 0
def score(self, x, y):
return np.mean(self.predict(x) == y.reshape(-1, 1))
def update_val_loss(self, x_val, y_val):
z = self.forpass(x_val)
a = self.sigmoid(z)
a = np.clip(a, 1e-10, 1-1e-10)
val_loss = np.mean(-(y_val*np.log(a) + (1-y_val)*np.log(1-a)))
self.val_losses.append(val_loss)
1. __init__() 메서드 수정하기
def __init__(self, n_cells=10, batch_size=32, learning_rate=0.1):
self.n_cells = n_cells
self.batch_size = batch_size
self.w1h = None
self.w1x = None
self.b1 = None
self.w2 = None
self.b2 = None
self.h = None
self.losses = []
self.val_losses = []
self.lr = learning_rate은닉층의 개수 대신 셀 개수를 입력받고, 셀에 필요한 가중치 w1h, w1x를 선언하며, 타임 스텝을 거슬러 그래이디언트를 전파하려면 활성화 출력을 모두 저장하고 있어야 하므로 변수 h를 선언합니다.
2. 가중치 초기화하기
def init_weights(self, n_features, n_classes):
orth_init = tf.initializers.Orthogonal()
glorot_init = tf.initializers.GlorotUniform()
self.w1h = orth_init((self.n_cells, self.n_cells)).numpy()
self.w1x = glorot_init((n_features, self.n_cells)).numpy()
self.b1 = np.zeros(self.n_cells)
self.w2 = glorot_init((self.n_cells, n_classes)).numpy()
self.b2 = np.zeros(n_classes)순환 신경망에서는 직교 행렬 초기화(orthogonal initialization)을 사용합니다. 이 방법은 순환 셀에서 은닉 상태에 가중치가 반복해서 곱해질 때, 너무 커지거나 작아지지 않도록 해줍니다.
3. 정방향 계산 구현하기
def forpass(self, x):
self.h = [np.zeros((x.shape[0], self.n_cells))]
seq = np.swapaxes(x, 0, 1)
for x in seq:
z1 = np.dot(x, self.w1x) + np.dot(self.h[-1], self.w1h) + self.b1
h = np.tanh(z1)
self.h.append(h)
z2 = np.dot(h, self.w2) + self.b2
return z2먼저, 각 스텝의 은닉 상태를 저장하기 위한 h를 0으로 초기화합니다. 정방향 계산을 가장 처음 실행할 때는 이전의 은닉 상태가 없기 때문입니다.
그 후, 입력의 첫 번째 배치 차원과 두 번째 타임 스텝의 차원을 바꿉니다.

우리가 사용할 데이터로 예를 들면, 각각의 리뷰가 샘플이고, 리뷰 안에서 각 단어들이 순서대로 타임스텝1, 타임스텝2... 입니다. 샘플의 수는 배치 사이즈와 같습니다.
배치 차원과 타임 스텝의 차원을 바꾸는 이유는 그림을 보면 이해하기 쉽습니다. 순환 신경망의 구조를 보면, 한 샘플의 모든 타임스텝을 처리하는 것이 아니라, 한 타임 스텝의 모든 샘플을 처리하는 방식입니다.
이렇게 차원을 바꾸고 나면, 반복문을 사용하여 타임 스텝대로 활성화 출력을 저장합니다.
4. 역방향 계산 구현하기
def backprop(self, x, err):
m = len(x)
w2_grad = np.dot(self.h[-1].T, -err) / m
b2_grad = np.sum(-err) / m
seq = np.swapaxes(x, 0, 1)
w1h_grad = w1x_grad = b1_grad = 0
err_to_cell = np.dot(-err, self.w2.T) * (1 - self.h[-1]**2)
for x, h in zip(seq[::-1][:10], self.h[:-1][::-1][:10]):
w1h_grad += np.dot(h.T, err_to_cell)
w1x_grad += np.dot(x.T, err_to_cell)
b1_grad += np.sum(err_to_cell, axis=0)
err_to_cell = np.dot(err_to_cell, self.w1h) * (1 - h**2)
w1h_grad /= m
w1x_grad /= m
b1_grad /= m
return w1h_grad, w1x_grad, b1_grad, w2_grad, b2_grad
역방향 계산을 할 때, 시간을 거꾸로 올라가야 하므로 seq[::-1]을 사용해 배열을 거꾸로 뒤집었습니다. 은닉 상태를 저장항 h의 마지막 항목, 즉 현재 타임 스텝의 활성화 출력은 err_to_cell 계산을 위해 계산했으므로, 이를 제외하고 나머지 활성화 출력들을 self.h[:-1][::-1]을 사용해 뒤집었습니다.
이렇게 뒤집고 나서, [:10]으로 슬라이싱해서 최근 10개의 타임 스텝만 진행합니다. 순환 신경망은 타임 스텝을 거슬러 올라가며 그래이디언트를 전파할 때, 같은 가중치를 계속 곱합니다. 이로 인해 그래이디언트가 너무 커지거나 작아질 수 있기 때문에 타임 스텝의 수를 제한해야 하는데, 이를 TBTT(Truncated Backpropagation Through Time)이라고 합니다.
err_to_cell은 다음 식을 의미합니다.

신경망 훈련하고 확인하기
rn = RecurrentNetwork(n_cells=32, batch_size=32, learning_rate=0.01)
rn.fit(x_train_onehot, y_train, epochs=20, x_val=x_val_onehot, y_val=y_val)
%matplotlib inline
import matplotlib.pyplot as plt
plt.plot(rn.losses)
plt.plot(rn.val_losses)
plt.show()
rn.score(x_val_onehot, y_val)

정확도가 약 67퍼센트 정도 나왔습니다. 이 결과는 글로럿 초기화의 결과에 따라 달라지므로, 실행 시마다 다른 결과가 나옵니다.
텐서플로를 사용하여 신경망 만들기
모델 만들기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN
model = Sequential()
model.add(SimpleRNN(32, input_shape=(100, 100)))
model.add(Dense(1, activation='sigmoid'))
model.summary()
input_shape는 타임 스텝의 길이가 100이고, 원-핫 인코딩 크기가 100이므로 입력 크기는 (100, 100)입니다. 이진 분류이므로 출력층은 1개의 유닛을 가지고, 활성화 함수는 시그모이드 함수입니다.
입력은 원-핫 인코딩된 100차원 벡터입니다. 입력의 형태는 100개의 타임 스텝을 가진 100차원 벡터가 배치 개수만큼 있습니다. 셀의 개수는 32개이므로, 따라서 이 입력과 곱해지는 가중치 $\mathbf{W}_{1x}$의 크기는 (100, 32)이고, 여기서 훈련되는 파라미터의 수는 절편을 포함해서 (100+1)*32 = 3232개 입니다.
순환 층에서 곱해지는 가중치 $\mathbf{W}_{1h}$의 크기는 (32, 32)입니다. 따라서 여기서 훈련되는 파라미터 수는 32*32 = 1024개 입니다. 순환 층의 전체적인 구조를 나타낸 그림을 보시면, 순환 층에서는 훈련되는 절편은 없습니다. 따라서, 순환 층에서 학습될 파라미터의 총 수는 4256개 입니다.
모델 훈련하고 손실, 정확도 그래프 확인하기
%matplotlib inline
import matplotlib.pyplot as plt
model.compile(optimizer='sgd', loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(x_train_onehot, y_train, epochs=20, batch_size=32,
validation_data=(x_val_onehot, y_val))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.show()
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.show()

훈련 결과 약 70%의 정확도를 보여주는데, 이전의 결과와 비교해보면 썩 나은 것 같지는 않습니다.
임베딩층으로 순환 싱경망 모델의 성능 높이기
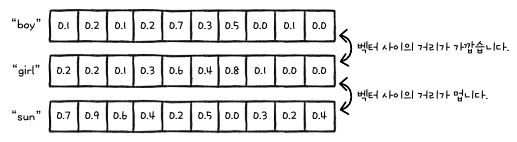
앞에서 만든 신경망의 가장 큰 단점 중 하나는, 데이터를 원-핫 인코딩으로 전처리했다는 것입니다. 원-핫 인코딩을 사용하면 입력 데이터 크기와 사용할 수 있는 단어의 수가 제한됩니다. 또한, '각 단어 들은 독립적이어야 한다'는 가정이 전제되어야 합니다. 독립에 대한 의미는 앞에서 설명했습니다. 앞에서 설명한 의미 말고도 또 다른 예시를 들자면, "boy"와 "girl"은 분명히 서로 관련이 있는 단어입니다. "boy"와 "son" 혹은 "girl"과 "daughter", "baby"와 "kid"도 서로 매우 관련이 있는 단어이지만, 원-핫 인코딩은 이런 관계를 표현하지 못합니다.

단어 임베딩(word embedding)을 사용하면 이 문제를 해결할 수 있습니다. 단어 임베딩은 아래 그림과 같이 단어를 고정된 길이의 벡터로 임베딩합니다.
모델 만들기
from tensorflow.keras.layers import Embedding
(x_train_all, y_train_all), (x_test, y_test) = imdb.load_data(skip_top=20, num_words=1000)
for i in range(len(x_train_all)):
x_train_all[i] = [w for w in x_train_all[i] if w > 2]
x_train = x_train_all[random_index[:20000]]
y_train = y_train_all[random_index[:20000]]
x_val = x_train_all[random_index[20000:]]
y_val = y_train_all[random_index[20000:]]
이번에는 1000개의 단어를 사용합니다. 단어 임베딩은 단어를 표현하는 벡터의 크기를 임의로 지정할 수 있으므로, 사용하는 단어의 개수에 영향을 받지 않습니다. 원-핫 인코딩에서는 단어 하나 당 벡터 하나에 대응했기 때문에, 사용하는 단어의 개수만큼 큰 벡터가 필요했습니다.
maxlen = 100
x_train_seq = sequence.pad_sequences(x_train, maxlen=maxlen)
x_val_seq = sequence.pad_sequences(x_val, maxlen=maxlen)
model_ebd = Sequential()
model_ebd.add(Embedding(1000, 32))
model_ebd.add(SimpleRNN(8))
model_ebd.add(Dense(1, activation='sigmoid'))
model_ebd.summary()타임 스텝의 길이가 100인 시퀀스 데이터를 만들고, 단어 임베딩에서 사용할 단어는 1000개, 벡터의 크기는 32인 벡터를 만듭니다. 또한, 셀의 개수를 8개로 크게 줄입니다.
훈련하고, 그래프 및 정확도 확인하기
model_ebd.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history = model_ebd.fit(x_train_seq, y_train, epochs=10, batch_size=32,
validation_data=(x_val_seq, y_val))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.show()
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.show()
loss, accuracy = model_ebd.evaluate(x_val_seq, y_val, verbose=0)
print(accuracy)


더 적은 셀을 사용했지만, 단어 임베딩을 사용해서 더 높은 성능을 냈습니다만, 정확도는 아직 80%정도에 불과합니다.
LSTM 순환 신경망
순환 신경망을 구현하면서, 그래이디언트가 타임 스텝을 거슬러 올라갈 때, 같은 가중치가 계속해서 곱해지기 때문에 그래이디언트가 크게 증가하거나 감소하는 현상이 생기고, 이를 해결하기 위해 가장 단순한 방법인 TBPTT를 구현했습니다. 하지만 이 방법은 그래이디언트가 타임 스텝 끝까지 전파되지 않으므로, 타임 스텝이 멀리 떨어진 단어 사이의 관계를 파악하기 어렵습니다.
LSTM(Long Short-Term Memory) 순환 신경망은 좀 더 긴 타임 스텝의 데이터를 처리할 수 있습니다.
LSTM 셀의 구조

LSTM은 2개의 출력이 순환되고, 그 중 하나의 출력만 다음 층으로 전달됩니다. 다음 층으로 전달되지 않고, 셀에서 순환만 되는 출력을 셀 상태(C)라고 합니다.

구조가 꽤 복잡한데, 하나씩 살펴보겠습니다.
위 그림에서 밑에 있는 4개의 $\mathbf{Z}_f, \mathbf{Z}_i, \mathbf{Z}_j, \mathbf{Z}_o$를 확인해보겠습니다. 이 4개의 $\mathbf{Z}$는 각각 다른 가중치와 절편인 $\mathbf{W}_{xi}, \mathbf{W}_{hi}, \pmb{b}_i, \mathbf{W}_{xj}, \mathbf{W}_{hj}, \pmb{b}_j, \mathbf{W}_{xo}, \mathbf{W}_{ho}, \pmb{b}_o$와 절편을 사용하여 구해집니다. 예를 들면, 다음과 같습니다.
$\mathbf{Z}_f = \mathbf{XW}_{xf}+\mathbf{H}_p\mathbf{W}_{hf}+\pmb{F}$
위 그림의 각 셀에서 계산되는 값은 다음과 같습니다.

$\mathbf{F}$를 계산하는 식은 이전 셀 상태의 내용을 삭제하는 역할을 해서 삭제 게이트(forget gate)라고 합니다.
$\mathbf{I}$를 계산하는 식은 새로운 정보를 추가하는 역할을 해서 입력 게이트(input gate)라고 합니다.
$\mathbf{H}$를 계산하는 식은 출력 게이트(output gate)라고 합니다.
위 게이트의 역할은 데이터 세트나 상황에 따라 달라질 수도 있습니다.
텐서플로로 LSTM 순환 신경망 만들기
1. 순환 신경망 만들기
from tensorflow.keras.layers import LSTM
model_lstm = Sequential()
model_lstm.add(Embedding(1000, 32))
model_lstm.add(LSTM(8))
model_lstm.add(Dense(1, activation='sigmoid'))
model_lstm.summary()
2. 모델 훈련하고, 결과 확인하기
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.show()
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.show()
loss, accuracy = model_lstm.evaluate(x_val_seq, y_val, verbose=0)
print(accuracy)

