[Deep Learning with Python] 3. 컴퓨터 비전을 위한 딥러닝
이번 포스트는 케라스 창시자에게 배우는 딥러닝(Deep Learning with Python)의 ch.5를 참고하였습니다.
이번 포스트를 읽기 전에, [Do it!] 시리즈를 먼저 읽는것을 권장합니다. 이 포스트에서는 [Do it!] 시리즈에 중복해서 나온 내용들을 많이 생략하였습니다.
이 책은 딥 러닝의 입문서로서는 적절하지 않다고 생각됩니다. 딥 러닝에 대한 어느정도 지식이 있고, 케라스의 사용방법에 대해 좀 더 자세히 알고 싶은 분께 권장합니다.
합성곱 신경망
합성곱 연산
완전 연결 층과 합성곱 층의 근본적인 차이는 다음과 같습니다.
- Dense 층은 입력 특성 공간에 있는 전역 패턴을 학습합니다.
- 합성곱 층은 지역 패턴을 학습합니다.
합성곱 층에서 지역 패턴을 학습할 때는 일반적으로 3x3 또는 5x5 크기의 윈도우를 사용합니다.
이런 특징은 합성곱 신경망에 두 가지 성질을 제공합니다.
- 학습된 패턴은 이동 불변성을 가집니다. 즉, 합성곱 신경망이 그림의 오른쪽 아래에서 어떤 패턴을 학습했다면, 다른 위치에 있는 같은 패턴이 있을 때, 이 패턴을 인식할 수 있습니다. 완전 연결 층은 새로운 위치에 나타난 것은 새로운 패턴으로 학습해야 합니다. 이 성질은 합성곱 신경망이 이미지를 효율적으로 처리할 수 있도록 해줍니다. 즉, 적은 수의 훈련 샘플을 사용해서 일반화 능력을 가진 표현을 학습할 수 있습니다.
- 합성곱 신경망은 공간적 계층 구조를 학습할 수 있습니다. 첫 번째 합성곱 층이 작은 지역 패턴을 학습하면, 두 번째 합성곱 층은 첫 번째 합성곱의 특성으로 구성된 더 큰 패턴을 학습하는 식입니다. 이런 방식을 사용하면 매우 복잡하고 추상적인 시각적 개념을 효과적으로 학습할 수 있습니다.
공간적 계층 구조에 대한 개념을 이해하기 위해 아래 그림을 보겠습니다.
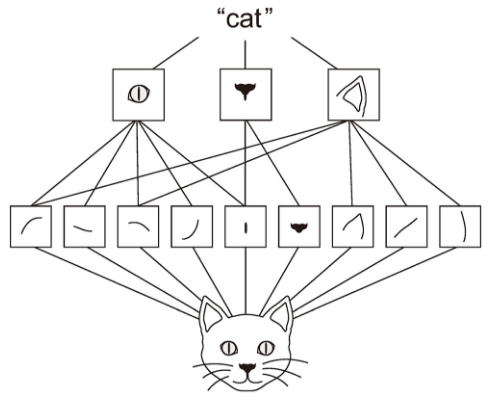
우리가 어떤 물체가 고양이인지를 판단할 때, 먼저 맨 아래층에 있는 세부적인 특징을 알아봅니다. 그리고 그 특징이 모이면 "첫번째 특징들로 구성된 눈", "첫번째 특징들로 구성된 코", "첫번째 특징들로 구성된 귀"가 됩니다. 그리고, 이 특징들이 모이면 "두번째 특징들로 구성된 물체"가 됩니다. 이렇게 세부적인 부분에서 점점 전체적인 특징이 되어가면서 이 물체가 무엇인지 판단하게 되는 것입니다.
합성곱 연산은 특성 맵(feature map)이라고 하는 3D 텐서에 적용됩니다. 이 텐서는 높이와 너비로 구성된 공간 축과 깊이 축(채널 축)으로 구성됩니다. RGB 이미지의 경우 깊이 축의 차원은 3이고, 흑백 이미지의 경우 깊이 축의 차원은 1입니다.
이전의 포스트 에서 합성곱 신경망을 사용하여 손글씨를 분류했던 예제에서 사용했던 모델의 구조를 다시 한번 확인해보겠습니다.

이 모델에서 conv2d 층은 (3, 3)크기의 필터 10개를 사용하여 same padding 방법으로 합성곱을 실행하였습니다. 따라서 그 출력으로는 (28, 28, 10) 크기의 특성 맵이 나오게 됩니다. 10개의 출력 채널은 각각 (28, 28)크기의 배열 값을 갖게 되며, 이 갑은 입력에 대한 필터의 응답 맵(response map)이라고 합니다. 즉, 입력의 각 위치에서 필터 패턴에 대한 응답을 의미합니다. 다음 그림을 한번 보겠습니다.

주어진 입력에 대해 필터를 적용하면, 오른쪽과 같은 응답 맵이 나옵니다. 이 그림의 경우, 응답 맵을 보면 원본 입력에서 필터와 같은 패턴을 보이는 곳이 더 밝게 나타나는 경향이 보입니다.
따라서, 특성 맵이 의미하는 것은, 깊이 축에 있는 각각의 차원은 하나의 특성(필터)이고(합성곱을 하면서 필터 하나 당 하나의 차원(특성)씩 추가되기 때문입니다.), 2D 텐서 output[:, :, n]은 입력에 대한 각 필터의 응답을 나타내는 2D 공간상의 맵입니다.
최대 풀링 연산
최대 풀링 연산을 하는 이유에 대해 좀 더 알아보겠습니다.
최대 풀링 연산을 하지 않는다면, 다음과 같은 문제가 있습니다.
- 특성의 공간적 계층을 학습하는데 도움이 되지 않습니다.
- 최종 특성 맵을 펼쳐서 완전 연결층의 입력으로 넣어야 하는데, 이때 학습해야 할 가중치가 너무 많게 됩니다.
예를 들어 입력이 (28, 28)크기의 이미지이고, (3, 3)크기의 밸리드 패딩을 하는 합성곱층이 3개가 있다고 가정해보겠습니다. 그러면 첫 번째 층에서의 출력은 (26, 26)이고, 두 번째 층에서의 출력은 (24, 24), 세 번째 층에서의 출력은 (22, 22)입니다. 여기서 세 번째 층에서의 윈도우는 초기 입력에서의 (7, 7)크기의 입력에 대한 정보밖에 담지 못합니다. 이전에 언급했듯이, 공간적 계층은 점진적으로 물체에 대한 전체적인 특징을 잡아내야 하는데, 원본 입력 (28, 28)에 비하면 (7, 7)으로는 전체적인 특징을 잡아낼 수 없습니다. (28, 28)크기의 이미지에서 (7, 7) 이미지만을 갖고 이게 무슨 이미지인지 맞춰본다고 생각해보세요. 쉽지 않을 것으로 보입니다.
왜 입력 층에서의 (7, 7) 크기를 사용하게 되는지는 다음과 같습니다.
마지막 층에서의 (3, 3)크기의 출력을 위해서는 두 번째 층에서의 (5, 5)만큼의 데이터가 필요합니다.
두 번째 층의 (5, 5)크기의 데이터를 위해서는 첫 번째 층에서의 (7, 7)만큼의 데이터가 필요합니다.
아직도 이해가 안되신다면, (7, 7)크기의 데이터에 (3, 3)크기의 윈도우를 갖고 밸리드 패딩을 2번 해보세요. 그럼 (3, 3)이 됩니다.
소규모 데이터셋으로 훈련하기
일반적으로 '적은' 샘플이랑 수만개 이하의 샘플을 의미합니다. 딥러닝은 데이터가 많을 때만 작동한다는 말이 있는데, 이는 부분적으로 맞는 말입니다. 딥러닝의 근본적인 특징은 훈련 데이터에서 특성 공학의 수작업 없이도 특성을 찾을 수 있다는 점입니다. 이는 훈련 샘플이 많아야 가능한데, 이미지같이 고차원적인 문제에서 특히 더 그렇습니다.
그러나 '많은 샘플'은 상대적인 의미입니다. 훈련하려는 네트워크의 크기와 깊이가 크면 그만큼 많은 샘플이 필요하고, 네트워크가 간단하면 샘플은 그리 많지 않아도 됩니다. 합성곱은 지역적이고 평행 이동으로 변하지 않는 특성을 학습하기 때문에 지각에 관한 문제에서는 데이터를 매우 효율적으로 사용합니다.
데이터 준비하기
먼저, 캐글 경연 홈페이지에서 데이터를 다운받습니다. 캐글 계정이 필요한데, 가입하는데 별로 오래 걸리지 않으니 회원가입 후, 데이터를 다운받으세요.
자신의 파이썬 실행 환경의 디렉토리에서, '/datasets/cats_and_dogs' 라는 디렉토리를 만들고, 그곳에 압축을 해제합니다.
그 후, 다음과 같이 코드를 입력하세요. 다음 코드의 입력이 귀찮다면, 직접 디렉토리를 만들고 파일을 복사해도 됩니다만, 파일의 경로를 저장하는 변수에 관한 코드는 입력해두세요.
import os, shutil
original_dataset_dir = './datasets/cats_and_dogs/train'
base_dir = './datasets/cats_and_dogs_small'
os.mkdir(base_dir)
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
fnames =['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
fnames =['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
fnames =['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
fnames =['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
fnames =['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)위 데이터셋은 훈련 데이터 25000개, 테스트 데이터 12500개가 있지만 우리는 데이터가 모자란 경우에 대한 훈련을 해볼것이므로, 훈련 및 검증용 고양이와 강아지 사진 3000개와 테스트용 고양이와 강아지 사진 1000개만을 사용해볼 것입니다.
네트워크 구성하기
이번에 만들어볼 네트워크는 150x150크기의 컬러 이미지를 입력으로 받는 네트워크입니다. 그리고 합성곱층과 풀링층을 번갈아가며 쌓아서 이 이미지를 7x7까지 줄이고, 일렬로 펼쳐서 완전 연결층에 입력으로 넣을 것입니다.
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3,), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3,), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
출력층의 활성화 함수로 시그모이드 함수를 사용한 이유는 분류할 종류가 2가지 뿐이기 때문입니다.
다음으로, 모델을 컴파일 합니다.
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])이진 분류 문제이므로 손실함수는 binary_crossentropy입니다. 옵티마이저로는 RMSprop를 사용합니다.
데이터 전처리
우리가 다운받은 이미지 파일들은 모두 JPEG 파일입니다. 따라서, 다음 과정을 거쳐서 전처리를 해줍니다.
1. 사진 파일 읽기
2. JPEG를 RGB 픽셀 값으로 디코딩하기
3. 부동 소수 타입 텐서로 반환하기
4. 0~255의 픽셀 값을 [0, 1]로 정규화하기
위 단계는 케라스의 ImageDataGenerator 클래스를 사용하면 간단하게 처리할 수 있습니다.
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')위 전처리의 결과, 훈련에 사용할 각각의 데이터의 크기는 (20, 150, 150, 3)입니다.
이제 모델을 훈련해보겠습니다.
history = model.fit_generator(train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)
model.save('cats_and_dogs_small_1.h5')데이터 생성 시, 배치 크기를 20으로 했고 데이터의 개수는 2000개이므로 steps_per_epoch는 100이고, 검증 세트의 데이터 개수는 1000개이므로 validation_steps는 50입니다. 총 30번의 에포크동안 훈련합니다.
훈련이 끝나면 모델을 항상 저장하는 것이 좋은 습관이라고 합니다. 따라서, line 7에서 훈련 후 해당 모델을 저장합니다.
이제, 훈련 결과를 그래프로 확인해보겠습니다.
%matplotlib inline
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()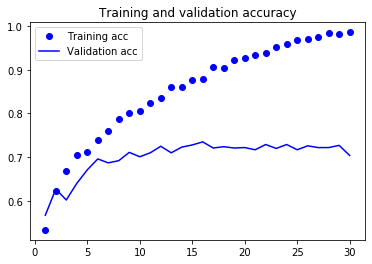
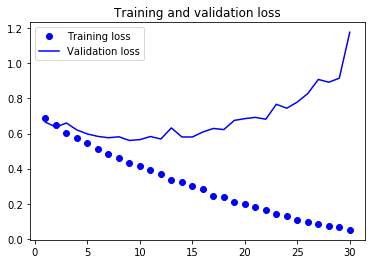
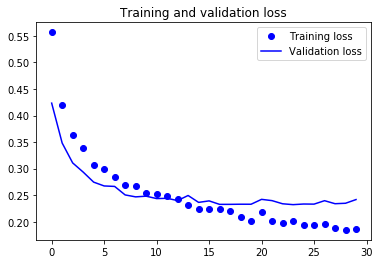
위 그래프를 보니 약 5번째 에포크에서 과대적합이 시작되는 것 같습니다. 이번 훈련에서는 적은 훈련 샘플(2000개)를 사용했기 때문에 과대적합을 해결하는 것이 매우 중요합니다. 이를 해결하기 위해서는 훈련 데이터의 수를 늘리거나, 드롭아웃을 사용하거나, 규제를 사용하는 방법이 있습니다. 이번에는 데이터 증식을 사용하여 훈련 데이터의 수를 늘려보겠습니다.
데이터 증식 사용하기
데이터 증식은 기존 훈련 샘플로부터 더 많은 훈련 데이터를 생성하는 방법입니다. 이 방법은 기존의 이미지에 여러 변환을 적용하여 샘플의 수를 늘립니다. 예를 들면 이미지를 회전하거나, 평행이동하는 등의 변환이 있습니다.
케라스에서는 ImageDataGenerator가 읽은 이미지에 여러 종류의 랜덤한 변환을 적용할 수 있습니다.
datagen = ImageDataGenerator(rotation_range=20,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
fill_mode='nearest')
rotation_range : 랜덤한 값으로 사진을 회전합니다. 단위는 deg입니다. 위의 경우 -20˚ ~ 20˚ 사이의 값으로 회전합니다.
width_shift_range, height_shift_range : 사진을 평행 이동합니다. 전체 너비와 높이에 대한 비율만큼 이동시킵니다. 만약 1보다 큰 실수 또는 정수를 지정해줄경우, 픽셀 값으로 간주됩니다.
shear_range : 전단 변환(shearing transformation)을 적용할 각도 범위입니다.
zoom_range : 사진을 확대할 범위입니다.
horizontal_flip : 이미지를 랜덤하게 수평으로 뒤집습니다.
fill_mode : 회전, 가로/세로 이동을 적용했을 때, 이미지의 빈 공간을 어떤 값으로 채울지를 정합니다.
증식된 데이터를 확인해보겠습니다.
from keras.preprocessing import image
fnames = sorted([os.path.join(train_cats_dir, fname) for
fname in os.listdir(train_cats_dir)])
img_path = fnames[3]
img = image.load_img(img_path, target_size=(150, 150)) # 이미지를 읽고 크기를 변경합니다
x = image.img_to_array(img) # (150, 150, 3) 크기의 넘파이 배열로 변환합니다
x = x.reshape((1,) + x.shape) # (1, 150, 150, 3) 크기로 변환합니다
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()



증식을 통해 생성된 이미지들은 적은 수의 원본 이미지를 통해 만들어졌기 때문에, 랜덤하게 변환이 적용되었다 해도 여전히 입력 데이터들 사이에 상호 연관성이 큽니다. 즉, 새로운 정보를 만들어 낼 수는 없고 기존 정보의 재조합만 가능하므로, 과대적합을 완전히 제거하기에는 충분하지 않을 수 있습니다. 따라서, 과대적합을 더 억제하기 위해 드롭아웃 층을 추가합니다.
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3,), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
데이터 증식을 사용하여 위 모델을 훈련해봅니다.
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
model.save('cats_and_dogs_small_2.h5')
혹시 다음과 같은 에러가 발생하면 텐서플로 2.2.0버전, 케라스는 2.3.1 버전으로 설치해보세요.
WARNING:tensorflow:Your input ran out of data; interrupting training. Make sure that your dataset or generator can generate at least `steps_per_epoch * epochs` batches (in this case, 10000 batches). You may need to use the repeat() function when building your dataset.
WARNING:tensorflow:Your input ran out of data; interrupting training. Make sure that your dataset or generator can generate at least `steps_per_epoch * epochs` batches (in this case, 50 batches). You may need to use the repeat() function when building your dataset.
다음으로, 훈련 결과를 확인해봅니다.
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()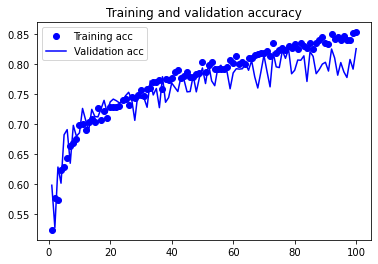
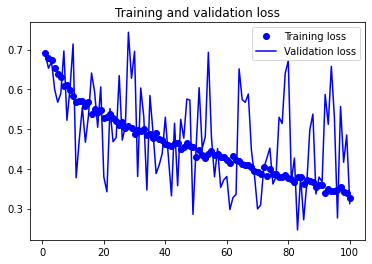
검증 결과의 정확도가 약 82%까지 상승했습니다. 다른 규제 기법을 사용하고 파라미터를 튜닝하면 약 87%정도까지 성능을 향상시킬 수 있지만, 데이터 자체가 부족하기 때문에 처음부터 높은 정확도를 달성하기는 어렵습니다.
사전에 훈련된 합성곱 신경망 사용하기
작은 이미지 데이터세트에 딥러닝을 적용하는 매우 효과적인 방법은 이미 훈련된 네트워크를 사용하는 것입니다. 사전에 훈련된 네트워크(pretrained network)는 일반적으로 대규모 이미지 분류 문제를 위해 대량의 데이터셋에서 미리 훈련되어 저장된 네트워크입니다.
이번에는 1400만개의 레이블된 이미지와 1000개의 클래스로 이루어진 ImageNet데이터셋에서 훈련된 합성곱 신경망을 사용해볼 것이며, VGG16이라는 구조를 가진 네트워크를 사용해볼 것입니다.
사전 훈련된 네트워크를 사용하는 방법에는 두 가지가 있는데, 특성 추출(feature extraction)과 미세 조정(fine tuning)이 있습니다.
특성 추출
특성 추출은 사전에 훈련된 네트워크의 표현을 사용하여 새로운 샘플에서 유용한 특성을 뽑아내는 것입니다. 이런 특성을 사용하여 새로운 분류기를 처음부터 훈련합니다.
이전에 보았듯이, 합성곱 신경망은 이미지 분류를 위해 두 부분으로 구성됩니다. 연속된 합성곱과 풀링층의 반복으로 시작하여 완전 연결 분류기로 끝나게 됩니다. 첫 번째 부분을 모델의 합성곱 기반 층(convolutional base)라고 하겠습니다. 합성곱 신경망의 경우, 특성 추출은 사전에 훈련된 네트워크의 합성곱 기반 층만 재사용하여 새로운 데이터를 통과시키고, 그 출력으로 새로운 분류기를 훈련합니다.

합성곱 층에 학습된 표현이 더 일반적이어서 재사용이 가능하므로, 완전 연결 분류기도 재사용할 수는 있으나, 일반적으로는 권장하지 않습니다. 합성곱 층의 특성 맵은 사진에 대한 일반적인 컨셉의 존재 여부를 기록한 맵이기 때문에, 주어진 컴퓨터 비전 문제에 상관없이 유용하게 사용할 수 있지만, 분류기에서 학습한 표현은 모델이 훈련된 클래스의 집합에만 특화되어있습니다.
또한, 완전 연결 층에서 찾은 표현은 더이상 입력 이미지에 있는 객체의 위치에 대한 정보를 갖고있지 않습니다. 따라서, 객체 위치가 중요한 문제라면 완전 연결 층에서 만든 특성은 크게 쓸모가 없습니다.
특정 합성곱 층에서 추출한 표현의 일반성 수준은 모델에 있는 층의 깊이에 의존합니다. 모델의 하위 층은 테두리(edge), 색깔, 질감 등 지역적이고 매우 일반적인 특성 맵을 추출하며, 상위 층은 '강아지 눈'이나 '고양이 귀'처럼 좀 더 추상적이고 디테일한 개념을 추출합니다. 만약 새로운 데이터셋이 원본 모델이 훈련한 데이터셋과 많이 다르다면, 전체 합성곱 기반 층을 사용하기 보다는 하의 층 몇개만 특성 추출에 사용하는 것이 좋습니다.
ImageNet의 클래스에는 여러 종류의 강아지와 고양이가 있습니다. 따라서 이번의 경우에는 그냥 원본 모델의 완전 연결 층에 있는 정보를 재사용해도 되지만, 새로운 문제의 클래스가 원본 모델의 클래스 집합과 겹치 않는 좀 더 일반적인 경우에 대해 생각해보기 위해 완전 연결 층을 사용하지 않을 것입니다.
이번에는 ImageNet 데이터셋에 훈련된 VGG16 네트워크 합성곱 기반 층을 사용하여 강아지와 고양이의 이미지에서 유용한 특성들을 추출해보고, 이 특성으로 강아지와 고양이를 분류하는 분류기를 훈련해볼 것입니다.
참고로, 케라스에서 사용 가능한 이미지 분류 모델은 다음과 같습니다.
- Xception
- Inception V3
- ResNet50
- VGG16
- VGG19
- MobileNet
이제 VGG16 모델을 만들어보겠습니다.
from keras.applications import VGG16
conv_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150, 150, 3))
conv_base.summary()
모델을 만들 때 사용했던 매개변수에 대해 알아보겠습니다.
- weights : 모델을 초기화할 가중치 체크포인트(checkpoint)를 지정합니다.
- include_top : 네트워크의 최상위 완전 연결 분류기를 포함할지를 지정합니다. 우리는 강아지와 고양이만을 구분하는 별도의 완전 연결 층을 추가할것이기 때문에 이를 포함하지 않습니다.
- input_shape : 네트워크에 주입할 이미지 텐서의 크기입니다. 이 값을 지정하지 않으면 어떤 크기의 입력도 처리할 수 있습니다.
위 네트워크에서 최종적인 특성 맵의 크기는 (4, 4, 512)입니다. 이제 이 특성 위에 완전 연결 층을 쌓을 것입니다. 여기서 사용 가능한 방식은 두 가지가 있습니다.
- 새로운 데이터셋에서 합성곱 기반 층을 실행하고 그 출력을 넘파이 배열 형식으로, 별도로 저장합니다. 그 후, 저장된 데이터를 독립된 완전 연결 분류기의 입력으로 사용합니다. 합성곱 연산은 전체 과정 중에서 계산 시간이 가장 많이 필요한 부분입니다. 이 방식은 모든 입력 이미지에 대해 합성곱 기반 층을 한 번만 실행하면 되기 때문에 빠르고 비용이 적게 들지만, 데이터 증식을 사용할 수 없습니다.
- 준비한 모델(conv_base)위에 Dense층을 쌓아 확장합니다. 그리고, 입력 데이터에서 end-to-end로 전체 모델을 실행합니다. 모델에 노출된 모든 이미지가 매번 합성곱 층을 통과하기 때문에 데이터 증식을 사용할 수 있지만, 계산이 훨씬 오래 걸립니다.
데이터 증식을 사용하지 않는 빠른 특성 추출
import os
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
base_dir = './datasets/cats_and_dogs_small'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 20
def extract_features(directory, sample_count):
features = np.zeros(shape=(sample_count, 4, 4, 512))
labels = np.zeros(shape=(sample_count))
generator = datagen.flow_from_directory(directory,
target_size=(150, 150),
batch_size=batch_size,
class_mode='binary')
i=0
for inputs_batch, labels_batch in generator:
features_batch = conv_base.predict(inputs_batch)
features[i*batch_size : (i + 1)*batch_size] = features_batch
labels[i*batch_size : (i + 1)*batch_size] = labels_batch
i += 1
if i*batch_size >= sample_count:
break
return features, labels
train_features, train_labels = extract_features(train_dir, 2000)
validation_features, validation_labels = extract_features(validation_dir, 1000)
test_features, test_labels = extract_features(test_dir, 1000)
추출된 특성의 크기는 (samples, 4, 4, 512)입니다. 따라서, 이를 완전 연결 분류기에 주입하기 위해 출력을 펼쳐야합니다.
train_features = np.reshape(train_features, (2000, 4*4*512))
validation_features = np.reshape(validation_features, (1000, 4*4*512))
test_features = np.reshape(test_features, (1000, 4*4*512))
그 후, 드롭 아웃을 적용한 완전 연결 분류기를 정의하고, 훈련해봅니다.
from keras import models
from keras import layers
from keras import optimizers
model = models.Sequential()
model.add(layers.Dense(256, activation='relu', input_dim=4*4*512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer=optimizers.RMSprop(lr=2e-5),
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(train_features, train_labels,
epochs=30,
batch_size=20,
validation_data=(validation_features, validation_labels))
훈련 결과를 그래프로 확인해봅니다.
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()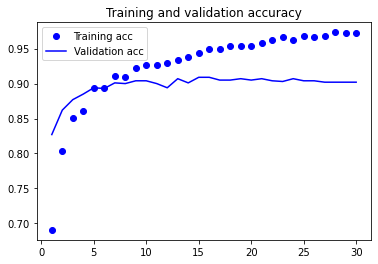
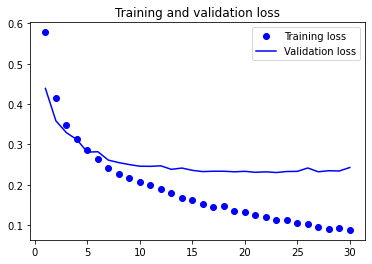
정확도가 약 90%정도로 나옵니다. 하지만, 드롭아웃을 50%로 적용했는데도 5~7번째 에포크 정도에서 금방 과대적합이 되어버리는 것을 볼 수 있습니다. 데이터셋이 작은데도 데이터 증식을 사용하지 않았기 때문입니다.
데이터 증식을 사용한 특성 추출
이 방법은 이전 방법에 비해 훈련하는데 비용이 많이 들지만, 데이터 증식 기법을 사용할 수 있습니다.
from keras import models
from keras import layers
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
완전 연결 층의 학습 파라미터는 약 200만개인데, 합성곱층의 파라미터는 약 1470만개로 훨씬 많네요.
이제 모델을 컴파일하고 훈련하기 전에, 반드시 해야하는 작업이 있는데 이는 합성곱 기반의 층을 동결해야하는 것입니다. 합성곱 기반의 층을 동결하지 않으면, 훈련하는 동안 기존에 이미 훈련되어있던 모델이 다시 훈련이 되어버려 의미가 없어지게 됩니다. 다음과 같이 동결하기 이전과 이후의 훈련 가능한 텐서의 수를 확인해볼 수 있습니다.
print(len(model.trainable_weights))
conv_base.trainable = False
print(len(model.trainable_weights))
위와 같이 설정하면 마지막에 추가한 2개의 Dense 층의 가중치만 훈련됩니다. 각 층마다 가중치 행렬과 편향(bias) 벡터 2개씩, 총 4개의 텐서가 훈련됩니다.
이제 데이터 증식을 사용하여 훈련해봅니다.
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=20,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
fill_mode='nearest')
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=2e-5),
metrics=['acc'])
history = model.fit_generator(train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50,
verbose=2)
결과 그래프는 다음과 같습니다
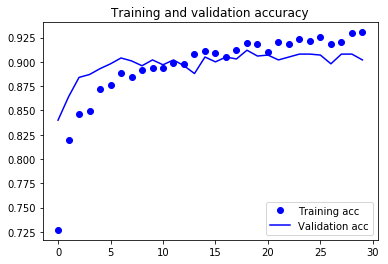
검증 정확도는 이전과 비슷하지만, 과대적합이 줄었습니다.
미세 조정
모델을 재사용할 때 많이 사용되는 또 다른 기법은 특성 추출을 보완하는 미세 조정(fine-tuning) 입니다. 미세 조정은 특성 추출에 사용했던 동결 모델의 상위 층 몇 개만 동결을 해제하고, 새로 추가한 층과 함께 훈련을 합니다.

참고로, 층을 위에서 아래로 쌓는 형태의 그림이 더 많습니다. 화살표의 방향에 유의하세요. 화살표 방향이 상위층으로 가는 방향입니다.
네트워크를 미세 조정하는 단계는 다음과 같습니다.
1. 사전에 훈련된 네트워크 위에 새로운 네트워크를 추가합니다.
2. 사전에 훈련된 네트워크를 동결합니다
3. 새로운 네트워크를 훈련합니다.
4. 사전에 훈련된 네트워크의 일부 층의 동결을 해제합니다.
5. 동결을 해제한 층과 새로 추가한 층을 같이 훈련합니다.

1~3번 단계는 이미 위에서 실행해보았습니다. 이제 마지막 합성곱 층인 block5_conv1~3층을 학습할 것입니다.
일부 상위 층만 미세조정하는 이유는 다음과 같습니다.
- 하위 층들은 좀 더 일반적인 특성들을 인코딩 합니다. 즉, 많은 사물에 적용될 수 있는 특성들을 인코딩하는 것입니다. 우리는 개와 고양이를 분류하는 새로운 문제를 해결하려고 하는 것이므로, 상위 층에 있는 좀 더 구체적인 특성을 미세 조정하는것이 유리합니다.
- 훈련해야 할 파라미터가 많을수록 과대적합의 위험이 커집니다. 합성곱 기반 층은 1470만개의 파라미터가 있으며, 작은 데이터 셋으로 전부 훈련하려 하면 과대적합의 위험이 매우 큽니다.
이제 미세 조정을 위해 상위 합성곱층만 동결하겠습니다.
conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
if layer.name=='block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
학습률을 낮춘 RMSProp 옵티마이저를 사용하여 훈련해봅니다. 학습률을 낮추는 이유는 미세 조정하는 상위 층에서의 이미 학습된 표현을 조금씩 수정하기 위해서입니다.
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-5),
metrics=['acc'])
history = model.fit_generator(train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
학습 그래프를 확인해보겠습니다.
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()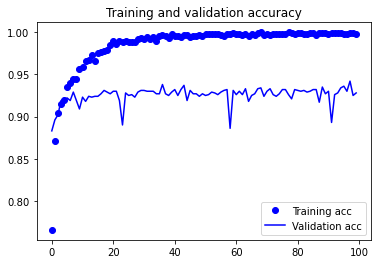
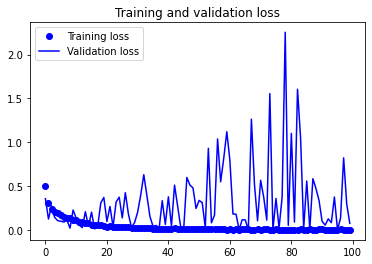
그래프가 너무 불규칙하게 보이므로, 지수 이동 평균을 사용하여 그래프가 좀 더 부드럽게 보이도록 해보겠습니다.
def smooth_curve(points, factor=0.8):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous*factor + point*(1 - factor))
else:
smoothed_points.append(point)
return smoothed_points
plt.plot(epochs,
smooth_curve(acc), 'bo', label='Smoothed training acc')
plt.plot(epochs,
smooth_curve(val_acc), 'b', label='Smoothed validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs,
smooth_curve(loss), 'bo', label='Smoothed training loss')
plt.plot(epochs,
smooth_curve(val_loss), 'b', label='Smoothed validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()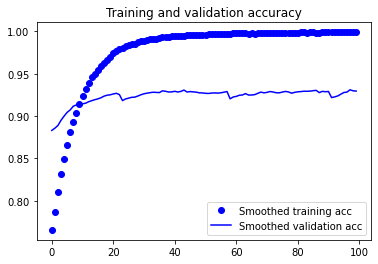
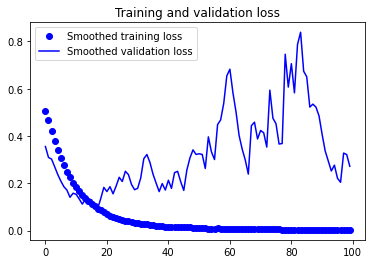
결과를 보면, 손실 곡선은 오히려 나빠졌지만, 검증 정확도는 더 좋아졌습니다. 손실이 감소되지 않았는데 정확도가 안정되거나 향상될 수 있는 이유는, 그래프는 개별적인 손실 값의 평균을 그린 것이기 때문입니다. 정확도에 영향을 미치는 것은 손실 값의 분포이지, 평균이 아닙니다. 분류 문제에서 정확도는 모델이 예측한 클래스가 임계 값을 넘었는지에 대한 결과입니다. 따라서 모델이 더 향상되더라도 평균 손실에는 반영되지 않을 수 있습니다.
다음으로, 테스트 데이터를 사용하여 평가해보겠습니다.
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=50)
print('test acc:', test_acc)
2000개의 데이터셋 만으로도 92%의 정확도를 얻었습니다.
합성곱 신경망 학습 시각화
보통 딥 러닝 모델을 블랙 박스(black box)같다고 합니다. 은닉 층에서 무슨 일이 일어나는지 사람이 이해하기는 어렵기 때문인데, 적어도 이미지를 처리하는 합성곱 신경망에서는 전혀 아닙니다. 다음 기법을 사용하면 중간 단계에서 이루어지는 표현들을 시각화하고 해석하기가 쉬워집니다.
- 합성곱 신경망 중간층의 출력을 시각화하기 : 연속된 합성곱층이 입력을 어떻게 변형시키는지 이해하고 개별적인 합성곱 신경망 필터의 의미를 파악하는데 도움이 됩니다.
- 합성곱 신경망 필터를 시각화하기 : 합성곱 신경망의 필터가 찾으려 하는 시각적 패턴과 개념이 무엇인지 아는데 도움이 됩니다.
- 클래스 활성화에 대한 히트맵(heatmap)을 이미지에 시각화하기 : 이미지의 어느 부분이 주어진 클래스에 속하는 데 얼마나 중요한지를 이해하고, 이미지에서 객체의 위치를 추정하는데 도움이 됩니다.
중간층의 출력 시각화하기
중간층의 출력은 입력이 주어졌을 때, 네트워크에 있는 각 합성곱과 풀링층이 출력하는 특성 맵을 그리는 것입니다. 이 방법은 학습된 필터들이 어떻게 입력을 분해하는지 보여줍니다. 각 채널은 독립적인 특성을 인코딩하므로 특성 맵의 각 채널 내용을 독립적인 2D 이미지로 그리면 이해하기 쉽습니다. 이전에 저장했던 모델을 불러와서 다시 사용해보겠습니다.
from keras.models import load_model
model = load_model('cats_and_dogs_small_2.h5')
model.summary()
그리고, 입력으로 사용할 고양이 사진 하나를 선택합니다.
img_path = './datasets/cats_and_dogs_small/test/cats/cat.1700.jpg'
from keras.preprocessing import image
import numpy as np
img = image.load_img(img_path, target_size=(150, 150))
img_tensor = image.img_to_array(img)
img_tensor = np.expand_dims(img_tensor, axis=0) # 이미지를 4D 텐서로 변경합니다.
img_tensor /= 255.
print(img_tensor.shape)
plt.imshow(img_tensor[0])
plt.show()

우리가 확인하려고 하는 특성 맵을 추출하기 위해 이미지 배치를 입력으로 받고, 모든 합성곱과 풀링 층의 활성화 출력을 계산하는 케라스 모델을 만들 것입니다. 이를 위해 케라스의 Model 클래스를 사용합니다.
모델 객체를 만들 때는 2개의 매개변수, 입력 텐서와 출력 텐서가 필요합니다. 리턴되는 객체는 Sequential과 같은 케라스 모델이지만 특정 입력과 특정 출력을 맵핑합니다.
from keras import models
layer_outputs = [layer.output for layer in model.layers[:8]] # 하위 8개 층의 출력을 추출합니다
activation_model = models.Model(inputs=model.input, outputs=layer_outputs)
위 코드를 통해 conv2d_5 ~ max_pooling2d_8 층들의 출력을 추출할 수 있습니다.
입력 이미지가 주입될 때, 이 모델은 원본 모델의 활성화 출력을 리턴합니다
activations = activation_model.predict(img_tensor)
first_layer_activation = activations[0]
print(first_layer_activation.shape)
첫 번째 합성곱층인 conv2d_5는 32개의 채널을 사용하고, 우리가 입력으로 넣은 이미지는 1개이므로 이 층에서의 출력은 (1, 148, 148, 32)입니다. 이 중에서 20번째와 15번째 채널의 출력을 확인해보겠습니다.
plt.matshow(first_layer_activation[0, :, :, 19], cmap='viridis')
plt.matshow(first_layer_activation[0, :, :, 15], cmap='viridis')


출력을 보아하니 20번째 채널은 대각선 방향의 에지(edge)를 감지하도록 인코딩 된 것 같습니다. 15번째 채널은 질감을 감지하는 것 같네요. 여러분들의 출력은 다를 수도 있습니다.
이번에는 모든 필터의 출력을 확인해보겠습니다.
layer_names = []
for layer in model.layers[:8]:
layer_names.append(layer.name)
n_cols = 16
for layer_name, layer_activation in zip(layer_names, activations):
#layer_activation.shape = (1, size, size, n_features)
n_features = layer_activation.shape[-1] # 채널 수
size = layer_activation.shape[1] # 이미지의 크기
n_rows = n_features // n_cols
display_grid = np.zeros((n_rows*size, n_cols*size))
for col in range(n_rows):
for row in range(n_cols):
channel_image = layer_activation[0, :, :, col*n_cols + row]
channel_image -= channel_image.mean()
channel_image /= channel_image.std()
channel_image *=64
channel_image += 128
channel_image = np.clip(channel_image, 0, 255).astype('uint8')
display_grid[col*size : (col + 1)*size,
row*size : (row + 1)*size] = channel_image
scale = 1. / size
plt.figure(figsize=(scale*display_grid.shape[1],
scale*display_grid.shape[0]))
plt.title(layer_name)
plt.grid(False)
plt.imshow(display_grid, aspect='auto', cmap='viridis')
plt.show()





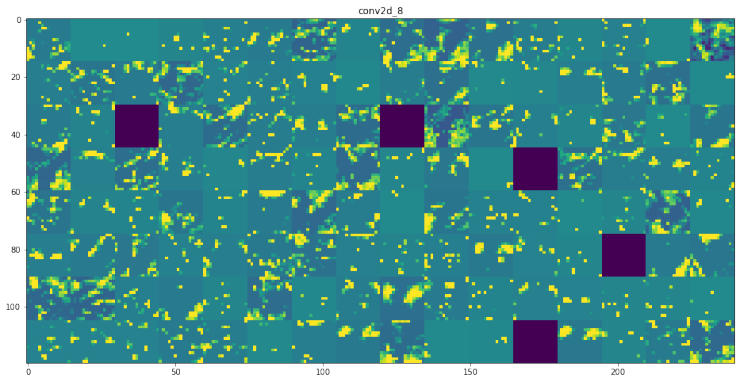

합성곱층을 통과할 때마다 점점 추상적으로 변해가는 모습을 볼 수 있습니다.
첫 번째 층은 거의 모든 정보가 유지되지만, 상위 층으로 갈 수록 점점 시각적으로 이해하기 어려워지고, 그냥 "고양이의 귀" 또는 "고양이의 눈" 정도만 알아볼 수 있습니다. 즉, 상위 층으로 갈 수록 이미지의 시각적 콘텐츠에 관한 정보는 줄고, 이미지의 클래스에 관한 정보가 증가합니다.
그리고 층이 깊어지면서 비어있는 활성화 출력이 있는데, 이는 필터에 인코딩 된 패턴이 입력 이미지에 나타나지 않았다는 것입니다.
층에서 추출한 특성은 층이 깊어짐에 따라 점점 추상적이게 됩니다. 높은 층의 활성화 출력은 입력에 관한 정보는 점점 줄어들고, 타깃에 관한 정보가 증가합니다. 즉, 반복적인 변환을 통해서 별로 유용하지 않은 정보는 제거되고, 유용한 정보는 강조됩니다.
사람도 물체를 인식하는 방식이 이와 비슷합니다. 자전거를 그려보라고 하면, 그림을 그리는 훈련을 받지 않은 일반적인 사람들은 대충 바퀴 2개에 프레임, 손잡이정도만 그리고, 세부적인 것은 그리지 못합니다. 즉, "자전거"하면 떠오르는 대표적인 부분만 그리는 것입니다. 이 부분이 "자전거"라는 물체에서 가장 중요한 부분인 것이고, 합성곱층은 이를 찾아내는 것입니다.
고양이의 얼굴을 그려보라고 하면 대부분 뾰족한 귀와 타원형의 눈을 그릴 것입니다. 이것들이 고양이를 구별하는데 가장 중요한 부분이기 때문이고, 합성곱층은 이런 부분을 잘 찾아내는 것을 확인할 수 있습니다.
합성곱층 필터 시각화하기
방금은 입력이 필터를 통과하고 난 후의 출력을 시각화 했지만, 이번에는 그 필터를 시각화 해보겠습니다.
합성곱이 학습한 필터를 조사하는 또다른 방법은 각 필터가 반응하는 시각적인 패턴을 그려보는 것입니다. 이를 위해서는 비어있는 입력 이미지에서 시작해서 특정 필터의 응답을 최대화하기 위해 입력 이미지에 경사 상승법을 적용합니다. 즉, 기존의 계산에서 반대로 가보는 것입니다. 그러면 필터가 어떤 형태의 이미지에 가장 잘 응답하는지 알아볼 수 있습니다.
이를 위한 과정은 먼저 합성곱 층의 한 필터 값을 최대화 하는 손실 함수를 정의합니다. 이 값을 최대화하기 위해서는 입력 이미지를 변경하도록 확률적 경사 상승법을 사용합니다.
그 과정은 다음과 같습니다.
from keras.applications import VGG16
from keras import backend as K
model = VGG16(weights='imagenet', include_top=False)
layer_name = 'block3_conv1'
filter_index = 0
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:, :, :, filter_index])ImageNet에 사전 훈련된 VGG16 네트워크에서 bolck_conv1 층에서 0번째 필터의 활성화를 손실로 정의합니다.
grads = K.gradients(loss, model.input)[0]
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)경사 상승법을 구현하기 위한 모델의 입력에 대한 손실의 그래이디언트는 케라스의 backend 모듈에 있는 gradients 함수를 사용합니다. 경사 상승법 과정을 부드럽게 하기 위해서는 그래이디언트 텐서를 L2 norm으로 나눠서 정규화하는 것입니다.
iterate = K.function([model.input], [loss, grads])
import numpy as np
loss_value, grads_value = iterate([np.zeros((1, 150, 150, 3))])케라스 백엔드 함수를 사용하여 주어진 입력 이미지에 대해 손실 텐서와 그래이디언트 텐서를 계산합니다. iterate는 넘파이 텐서를 입력으로 받아 손실과 그래이디언트 텐서를 반환합니다.
input_img_data = np.random.random((1, 150, 150, 3))*20 + 128.
step = 1.
for i in range(40):
loss_value, grads_value = iterate([input_img_data])
input_img_data += grads_value*step반복문을 만들어 확률적 경사 상승법을 구현합니다. 이 결과의 이미지 텐서는 (1, 150, 150, 3) 크기의 부동 소수 텐서입니다. 이 값은 [0, 255]범위의 정수가 아니므로, 출력 가능한 이미지로 변경하기 위해 아래와 같이 후처리를 해줍니다.
def deprocess_image(x):
x -= x.mean()
x /= (x.std() + 1e-5)
x *= 0.1
x += 0.5
x = np.clip(x, 0, 1)
x *= 255
x = np.clip(x, 0, 255).astype('uint8')
return x
이제 위에서 설명한 코드를 통해 층의 이름과 필터 번호를 입력으로 받아서 필터의 패턴을 출력하는 함수를 만들어보겠습니다.
def generate_pattern(layer_name, filter_index, size=150):
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:, :, :, filter_index])
grads = K.gradients(loss, model.input)[0]
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
iterate = K.function([model.input], [loss, grads])
input_img_data = np.random.random((1, size, size, 3))*20+128.
step=1.
for i in range(40):
loss_value, grads_value = iterate([input_img_data])
input_img_data += grads_value*step
img = input_img_data[0]
return deprocess_image(img)
plt.imshow(generate_pattern('block3_conv1', 0))
block3_conv1 층은 이런 동그란 무늬 패턴에 반응하는 것 같습니다. 이제 모든 층에 있는 필터를 시각화해볼 것인데, 각 층별로 처음 64개의 필터만 시각화할 것입니다. 그리고, 각 필터의 출력 사이에 검은색 마진을 약간 둬서 구별하기 편하게 할 것입니다.
layer_name = 'block1_conv1'
size = 64
margin = 5
# 검은색 마진
results = np.zeros((8*size + 7*margin, 8*size + 7*margin, 3), dtype='uint8')
for i in range(8):
for j in range(8):
filter_img = generate_pattern(layer_name, i + (j*8), size=size)
horizontal_start = i*size + i*margin
horizontal_end = horizontal_start + size
vertical_start = j*size + j*margin
vertical_end = vertical_start + size
results[horizontal_start: horizontal_end,
vertical_start: vertical_end, :] = filter_img
plt.figure(figsize=(20, 20))
plt.imshow(results)
block1_conv1 층에서 처음 64개 필터의 패턴은 위와 같습니다.

block2_conv1 층에서 처음 64개 필터의 패턴입니다.

block3_conv1 층에서 처음 64개 필터의 패턴입니다.

block4_conv1 층에서 처음 64개 필터의 패턴입니다.
위 결과를 보니, block1과 block2 층에서는 대각선 방향 edge같은 일반적인 패턴을 감지하지만, 더 상위층을 갈 수록 깃털, 나뭇잎, 눈 같은 구체적인 패턴을 감지하는 것을 알 수 있습니다.
클래스 활성화의 히트맵 시각화하기
이 방법은 이미지의 어느 부분이 합성곱 신경망의 최종 분류 결정에 기여하는지 이해하는데 유용합니다. 분류기에 실수가 있는 경우, 합성곱 신경망의 결정 과정을 디버깅 하는데 도움이 됩니다. 또한, 이미지에서 물체의 위치 파악에도 사용할 수 있습니다.
이 기법의 종류를 클래스 활성화 맵(Class Activation Map, CAM) 시각화라고 합니다. 클래스 활성화 히트맵은 특정한 출력 클래스에 대한 입력 이미지의 모든 위치를 계산한 2D 점수 grid 입니다. 즉, 클래스를 구별하는데 있어서 각 위치가 얼마나 중요한지를 나타내는 것입니다.
이를 구현하기 위해 사용하는 방법은 Grad-CAM이라고 하며, 매우 간단합니다. 입력 이미지가 주어지면 합성곱 층에 있는 특성 맵을 추출하고, 특성 맵의 모든 채널 출력에 채널에 대한 클래스의 그래이디언트의 평균을 곱합니다.
이번에는 다음 이미지를 사용할 것입니다. 이 이미지를 저장하여 다음 예시를 실행해보세요.

VGG16을 위해 입력 이미지를 전처리합니다.
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input, decode_predictions
import numpy as np
model = VGG16(weights='imagenet')
img_path = './datasets/creative_commons_elephant.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
사전에 훈련된 네트워크에 이 이미지를 입력으로 넣고, 출력 결과를 확인해봅니다.
preds = model.predict(x)
print('Predicted : ', decode_predictions(preds, top=3)[0])
90%확률로 아프리카 코끼리, 8.6%확률로 코끼리(tusker), 0.4%확률로 인도 코끼리라고 하네요.
np.argmax(preds[0])
예측된 클래스는 386번 인덱스입니다. 이제 이 이미지에서 아프리카 코끼리를 가장 잘 나타내는 부위를 시각화하기 위해 Grad-CAM 처리 과정을 구현해봅니다.
african_elephant_output = model.output[:, 386] # 아프리카 코끼리의 인덱스
last_conv_layer = model.get_layer('block5_conv3')
# 아프리카 코끼리 클래스의 그래이디언트
grads = K.gradients(african_elephant_output, last_conv_layer.output)[0]
# 특성 맵 채널 별 그래이디언트 평균값이 담긴 (512,)크기의 벡터
pooled_grads = K.mean(grads, axis=(0, 1, 2))
# 샘플 이미지가 주어졌을 때, pooled_grads와 line3에서 지정한 합성곱층의 특성 맵 출력을 구합니다
iterate = K.function([model.input], [pooled_grads, last_conv_layer.output[0]])
# 이미지를 입력하고 2개의 넘파이 배열을 받습니다.
pooled_grads_value, conv_layer_output_value = iterate([x])
# 아프리카 코끼리 클래스에 대한 채널의 중요도를 특성 맵 배열의 채널에 곱합니다.
for i in range(512):
conv_layer_output_value[:, :, i] *= pooled_grads_value[i]
# 만들어진 특성 맵에서 채널 축을 따라 평균을 낸 값이 클래스 활성화의 히트맵입니다.
heatmap = np.mean(conv_layer_output_value, axis=-1)
heatmap = np.maximum(heatmap, 0)
heatmap /= np.max(heatmap)
plt.matshow(heatmap)
이제 이 이미지를 원본 이미지에 겹쳐보겠습니다.
import cv2
img = cv2.imread(img_path)
heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0]))
heatmap = np.uint8(255*heatmap)
heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)
superimposed_img = heatmap*0.4 + img
cv2.imwrite('./datasets/elephant_cam.jpg', superimposed_img)

cv2.imwrite()에 입력한 경로를 확인해보면 위와 같은 결과의 파일이 생성된 것을 확인할 수 있습니다. 위 결과를 보고 알 수 있는 점은 코끼리의 위치와, 왜 코끼리라고 판단했는지를 알 수 있습니다. 붉은색에 가까울수록 코끼리임을 판정하는데 중요한 부분이라는 의미입니다.