[Deep Learning with Python] 4-2. 순환 신경망 이해하기
이번 포스트는 케라스 창시자에게 배우는 딥러닝(Deep Learning with Python)의 ch.6을 참고하였습니다.
이번 포스트를 읽기 전에, [Do it!] 시리즈를 먼저 읽는것을 권장합니다. 이 포스트에서는 [Do it!] 시리즈에 중복해서 나온 내용들을 많이 생략하였습니다.
이 책은 딥 러닝의 입문서로서는 적절하지 않다고 생각됩니다. 딥 러닝에 대한 어느정도 지식이 있고, 케라스의 사용방법에 대해 좀 더 자세히 알고 싶은 분께 권장합니다.
완전 연결 신경망이나 합성곱 신경망의 특징은 메모리가 없다는 점입니다. 네트워크에 주입되는 입력은 독립적이며, 입력 간에 유지되는 상태가 없습니다. 이런 네티워크로 시퀀스나 시계열 데이터 포인트를 처리하기 위해서는 네트워크에 전체 시퀀스를 주입해야 합니다. 즉 IMDB 문제의 경우, 리뷰 하나를 큰 벡터 하나로 변환하여 처리하는 것입니다.
순환 신경망은 사람이 문장을 읽는 것처럼 이전에 나온 데이터를 기억하면서 단어별로 또는 한 눈에 들어오는 만큼씩 처리합니다. 이는 문장에 있는 의미를 자연스럽게 표현하도록 도와줍니다. 즉, 과거의 데이터 정보를 사용하며 데이터를 처리하는 것입니다.
순환 신경망은 시퀀스의 원소를 순회하며 지금까지 처리한 정보를 저장합니다. 순환 신경망에 대한 자세한 내용은 링크를 참조하세요.
케라스의 순환 층
케라스의 순환 층은 SimpleRNN 모듈에 구현되어있습니다. 이 층은 (batch_size, timesteps, input_features) 크기의 입력을 받습니다.
SimpleRNN은 두 가지 모드로 실행할 수 있는데, 각 타임스텝의 출력을 모은 전체 시퀀스를 리턴하거나(이 때, 출력의 크기는 (batch_size, timesteps, output_features)입니다), 입력 시퀀스에 대한 마지막 출력만 리턴할 수 있습니다(이 때, 출력의 크기는 (batch_size, output_featrues)입니다.) 이 설정은 객체를 생성할 때 매개변수 return_sequences를 통해서 설정합니다.
다음으로, 마지막 타임 스텝의 출력만 얻는 예시를 보겠습니다. SimpleRNN()의 매개변수로 들어간 값 32는 해당 층에서의 유닛의 개수입니다. 반드시 임베딩층의 차원과 같을 필요는 없습니다.
from keras.models import Sequential
from keras.layers import Embedding, SimpleRNN
model = Sequential()
model.add(Embedding(10000, 32))
model.add(SimpleRNN(32))
model.summary()

다음 예는 전체 상태 시퀀스를 리턴합니다.
model = Sequential()
model.add(Embedding(10000, 32))
model.add(SimpleRNN(32, return_sequences=True))
model.summary()
네트워크의 표현력 증가를 위해 여러 개의 순환 층을 차례대로 쌓아야 하는 경우도 있는데, 이럴 때는 중간층들이 전체 출력 시퀀스를 리턴하도록 설정해야 합니다.
model = Sequential()
model.add(Embedding(10000, 32))
model.add(SimpleRNN(32, return_sequences=True))
model.add(SimpleRNN(32, return_sequences=True))
model.add(SimpleRNN(32, return_sequences=True))
model.add(SimpleRNN(32))
model.summary()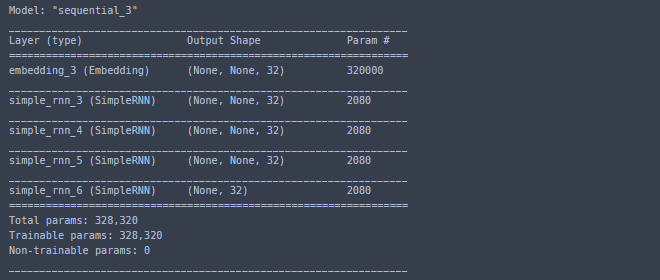
이제 IMDB 영화 리뷰 문제에 적용해볼 것입니다. 먼저, 데이터를 전처리합니다.
from keras.datasets import imdb
from keras.preprocessing import sequence
max_features = 10000
maxlen = 500
batch_size = 32
print('loading data...')
(input_train, y_train), (input_test, y_test) = imdb.load_data(num_words=max_features)
print(len(input_train), 'training sequence')
print(len(input_test), 'test sequence')
print('sequence padding (samples x time)')
input_train = sequence.pad_sequences(input_train, maxlen=maxlen)
input_test = sequence.pad_sequences(input_test, maxlen=maxlen)
print('input_train size : ', input_train.shape)
print('output_test size : ', input_test.shape)
다음으로, 임베딩층과 SimpleRNN층을 사용하여 간단한 RNN을 훈련시켜봅니다.
from keras.layers import Dense
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(SimpleRNN(32))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(input_train, y_train,
epochs=10, batch_size=128,
validation_split=0.2)
훈련 결과를 그래프로 확인해봅니다.
%matplotlib inline
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()

약 85%정도의 검증 정확도를 보여줍니다.
케라스를 이용한 LSTM 예제
SimpleRNN은 시간 t 이전의 모든 타임스텝의 정보를 유지할 수 있지만, 그래이디언트 소실 문제로 인해 긴 시간에 걸친 의존성은 학습할 수 없습니다. 이 문제를 해결하기 위해 고안된 것이 LSTM과 GRU 입니다.
이번에는 LSTM층으로 모델을 구성하고, IMDB 데이터를 사용하여 훈련해봅니다.
from keras.layers import Dense
%matplotlib inline
import matplotlib.pyplot as plt
from keras.layers import LSTM
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(LSTM(32))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(input_train, y_train,
epochs=10, batch_size=128,
validation_split=0.2)
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()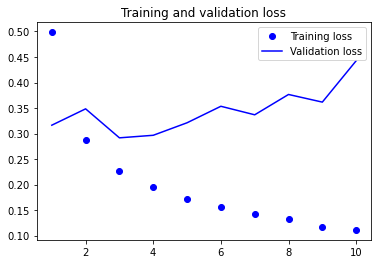
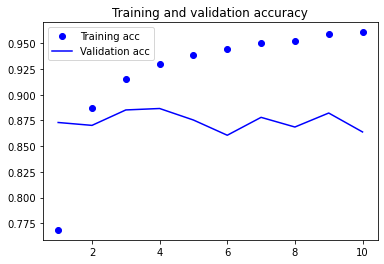
약 88%정도의 검증 정확도를 보여줍니다. 하지만 SimpleRNN에 비해 계산 시간이 꽤 오래걸렸는데, 이렇게 증가한 시간 치고는 획기적인 성능 향상은 보여주지 못했습니다. 이 이유 중 하나는 하이퍼파라미터를 튜닝하지 않았기 때문이고, 규제를 적용하지 않았기 때문입니다.
무엇보다 가장 큰 이유는, LSTM은 리뷰를 전체적으로 길게 분석하는 것을 잘 합니다만, 이는 감성 분류 문제에는 별 도움이 되지 않습니다. 감성 분류같이 간단한 문제는 각 리뷰에 어떤 단어가 나타나고 얼마나 등장하는지 보는 것이 더 낫습니다. LSTM은 이런 간단한 문제보다는 훨씬 더 복잡한 자연어 처리 문제에서 좋은 성능을 보여줍니다.