[Deep Learning with Python] 5-1. 케라스의 함수형 API
이번 포스트는 케라스 창시자에게 배우는 딥러닝(Deep Learning with Python)의 ch.7을 참고하였습니다.
이번 포스트를 읽기 전에, [Do it!] 시리즈를 먼저 읽는것을 권장합니다. 이 포스트에서는 [Do it!] 시리즈에 중복해서 나온 내용들을 많이 생략하였습니다.
이 책은 딥 러닝의 입문서로서는 적절하지 않다고 생각됩니다. 딥 러닝에 대한 어느정도 지식이 있고, 케라스의 사용방법에 대해 좀 더 자세히 알고 싶은 분께 권장합니다.
지금까지 사용했던 모든 신경망은 Sequential 모델을 사용해서 만들었습니다. Sequential 모델은 네트워크 입력과 출력이 하나라고 가정하며, 층을 차례대로 쌓아서 만들었습니다.

이런 모델이 잘 작동하는 경우도 많지만, 그렇지 않은 경우도 많습니다. 일부 네트워크는 입력이 여러개 필요하거나, 출력이 여러개 필요하기도 하고, 층을 차례대로 쌓지 않고 층 사이를 연결하여 그래프처럼 만들기도 합니다.
먼저, 다양한 종류의 입력이 필요한 예를 생각해보겠습니다. 예를 들어, 중고 의류의 시장 가격을 예측하는 딥 러닝 모델을 생각해봅니다. 이 모델은 사용자가 제공한 메타데이터(브랜드, 제작년도 등), 텍스트 설명, 제품 사진을 입력으로 사용합니다.
만약 메타데이터만 있다면 이를 원-핫 인코딩으로 바꾸고, 완전 연결 네트워크를 사용하여 가격을 예측할 수 있습니다. 텍스트 설명만 있다면 RNN 또는 1D 합성곱 신경망을 사용하면 되고, 사진 이미지만 있다면 2D 합성곱 신경망을 사용하면 됩니다.
하지만 이 3개를 모두 사용하려면 어떻게 해야할까요? 간단한 방법은 3가지 모델을 따로 훈련하고, 각 예측을 가중 평균(weighted average)하는 것입니다. 각 모델에서 추출한 정보가 중복된다면 이 방식은 최적화된 방식이 아닐 것입니다. 이 방식을 그림으로 그리면 다음과 같습니다.

이와 비슷하게, 어떤 작업은 출력이 여러개일 수도 있습니다. 예를 들어, 어떤 글이 있을 때 이를 장르별로 분류하는 문제를 생각해보겠습니다. 또한, 이 뿐만 아니라 글이 써진 시대 또한 예측해야한다고 해보겠습니다. 물론 2개의 모델을 따로 훈련할 수도 있지만, 통계적으로 이 속성들은 독립적이지 않습니다. 따라서, 장르와 시대를 함께 예측하도록 학습해야 더 좋은 모델을 만들 수 있습니다. 이 모델의 경우, 장르와 시대의 상관관계로 인해 소설 시대를 알면 장르의 공간에서 정확하고 풍부한 표현을 학습하는데 도움이 되며, 이 반대도 마찬가지입니다.

최근에 개발된 많은 신경망 구조는 선형적이지 않은 네트워크 토폴로지(topology)가 필요합니다. 비순환 유향 그래프 같은 네트워크 구조인데, 예를 들면 구글의 인셉션 모듈을 사용하는 인셉션 계열의 네트워크들 입니다. 이 모듈의 구조는 다음과 같습니다.

또한, 잔차 연결을 사용하는 모델도 있습니다. 마이크로소프트의 He가 개발한 ResNet 계열의 네트워크가 이런 방식을 사용합니다. 잔차 연결은 하위 층의 출력 텐서를 상위 층의 출력 텐서에 더해 아래층의 표현이 위쪽으로도 흘러갈 수 있도록 합니다. 즉, 하위 층에서 학습된 정보가 손실되는 것을 방지하는 것입니다.

위와 같은 구조들을 만들기 위해서는 일반적이고 유연한 함수형 API가 필요합니다. 지금까지 사용했던 Sequential 클래스로는 이런 구조를 만들지 못합니다.
함수형 API 소개
함수형 API(functional API)에서는 텐서들의 입출력을 직접 다룹니다. 함수처럼 층을 사용하여 텐서를 입력받고 출력합니다. 간단한 예시를 통해 Sequential 모델과 함수형 API로 만든 모델을 비교해보겠습니다.
from keras.models import Sequential, Model
from keras import layers
from keras import Input
seq_model = Sequential()
seq_model.add(layers.Dense(32, activation='relu', input_shape=(64,)))
seq_model.add(layers.Dense(32, activation='relu'))
seq_model.add(layers.Dense(10, activation='softmax'))
input_tensor = Input(shape=(64,))
x = layers.Dense(32, activation='relu')(input_tensor)
x = layers.Dense(32, activation='relu')(x)
output_tensor = layers.Dense(10, activation='softmax')(x)
model = Model(input_tensor, output_tensor)
seq_model.summary()
print("\n")
model.summary()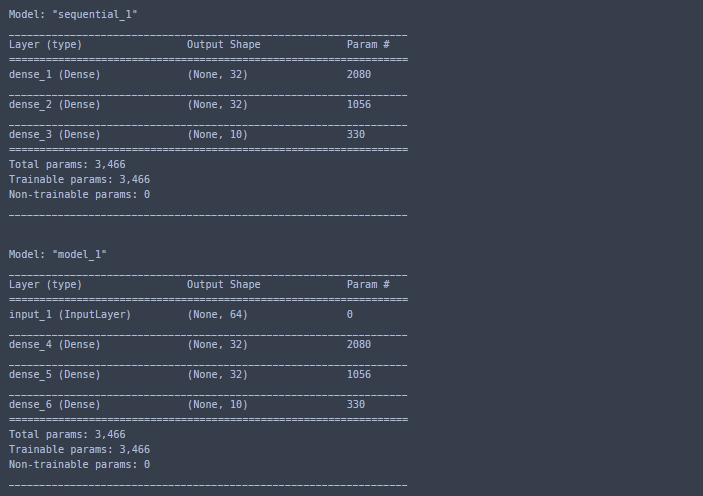
다중 입력 모델
함수형 API는 다중 입력 모델을 만들기 위해 사용할 수 있습니다. 일반적으로 이런 모델은 서로 다른 입력을 합치기 위해 여러 텐서를 연결할 수 있는 층을 사용합니다. 간단한 예로, 질문을 하면 응답을 하는 모델을 만들어보겠습니다.
전형적인 질문-응답 모델은 2개의 입력을 갖습니다. 하나는 자연어 질문이고, 다른 하나는 답변에 필요한 정보가 있는 텍스트(예를 들어, 뉴스 기사)입니다. 가장 간단한 구조는 소프트맥스 함수를 통해 미리 정의한 어휘 사전에서 한 단어로 된 답을 출력하는 것입니다.

함수형 API를 통해 위와 같은 구조를 만들어보겠습니다. 텍스트와 질문을 벡터로 인코딩하여 독립된 입력 2개를 정의하고, 이 벡터를 연결한 후에 소프트맥스 분류기를 추가합니다.
from keras.models import Model
from keras import layers
from keras import Input
text_vocabulary_size = 10000
question_vocabulary_size = 10000
answer_vocabulary_size = 500
# 길이가 정해지지 않은 정수 시퀀스의 입력. 이름은 'text'
text_input = Input(shape=(None,), dtype='int32', name='text')
# 크기가 64인 벡터 시퀀스
embedded_text = layers.Embedding(text_vocabulary_size, 64)(text_input)
encoded_text = layers.LSTM(32)(embedded_text)
question_input = Input(shape=(None,), dtype='int32', name='question')
embedded_question = layers.Embedding(question_vocabulary_size, 64)(question_input)
encoded_question = layers.LSTM(16)(embedded_question)
# 인코딩된 텍스트와 질문을 연결
concatenated = layers.concatenate([encoded_text, encoded_question], axis=-1)
answer = layers.Dense(answer_vocabulary_size, activation='softmax')(concatenated)
model = Model([text_input, question_input], answer)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['acc'])
model.summary()
훈련하는 방법에는 두 가지 방법이 있습니다. 넘파이 배열의 리스트를 입력하거나, 입력 이름과 넘파이 배열로 이루어진 딕셔너리를 입력으로 사용하는 방법입니다. 두 번째 방법은 처음에 층을 만들 때 이름을 입력해야 사용 가능합니다. 위의 예시에서는 'text', 'question'으로 이름을 정해줬습니다.
import numpy as np
from keras.utils import to_categorical
num_samples = 1000
max_length = 100
text = np.random.randint(1, text_vocabulary_size,
size=(num_samples, max_length))
question = np.random.randint(1, question_vocabulary_size,
size=(num_samples, max_length))
answers = np.random.randint(0, answer_vocabulary_size, size=num_samples)
answers = to_categorical(answers)
model.fit([text, question], answers, epochs=10, batch_size=128)
#또는
model.fit({'text': text, 'question': question}, answers,
epochs=10, batch_size=128)
다중 출력 모델
이와 비슷한 방법으로, 함수형 API를 사용해서 다중 출력 모델을 만들 수 있습니다. 예를 들어, 소셜 미디어의 포스트로부터 작성자의 나이와 소득, 성별을 예측하는 구조는 다음과 같습니다.

from keras import layers
from keras import Input
from keras.models import Model
vocabulary_size = 50000
num_income_groups = 10
posts_input = Input(shape=(None,), dtype='int32', name='posts')
embedded_posts = layers.Embedding(vocabulary_size, 256)(posts_input)
x = layers.Conv1D(128, 5, activation='relu')(embedded_posts)
x = layers.MaxPooling1D(5)(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.MaxPooling1D(5)(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.Conv1D(256, 5, activation='relu')(x)
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dense(128, activation='relu')(x)
age_prediction = layers.Dense(1, name='age')(x)
income_prediction = layers.Dense(num_income_groups,
activation='softmax',
name='income')(x)
gender_prediction = layers.Dense(1, activation='sigmoid', name='gender')(x)
model = Model(posts_input, [age_prediction, income_prediction, gender_prediction])
이런 모델을 훈련하기 위해서는 출력마다 다른 손실 함수를 지정해야 합니다. 나이 예측은 스칼라 회귀이므로 평균 제곱 오차를 사용하고, 수입 예측은 10개의 구간으로 나눴으므로 categorical_crossentropy를 사용하며, 성별은 이진 분류이므로 binary_crossentropy를 사용합니다.
경사 하강법은 하나의 스칼라 값을 최소화하기 때문에 모델을 훈련하기 위해서는 이 손실함수의 값들이 하나로 합쳐져야 합니다. 가장 간단한 방법은 그냥 더하는 것입니다
model.compile(optimizer='rmsprop',
loss=['mse', 'categorical_crossentropy', 'binary_crossentropy'])
model.compile(optimizer='rmsprop',
loss={'age': 'mse',
'income': 'categorical_crossentropy',
'gender': 'binary_crossentropy'})
하지만 각 손실함수 값이 많이 불균형하면, 그 손실 값이 큰 특정 작업에만 치우쳐서 학습을 할 것이며, 따라서 다른 작업에는 손해가 생깁니다. 이를 위해 각 손실 함수 값의 스케일이 다른경우, 각 값에 가중치를 적용할 수 있습니다. 나이를 예측할 때 생기는 평균 제곱 오차는 보통 3~5정도의 값을 갖지만, 성별 분류에 사용되는 크로스엔트로피 손실은 0.1정도입니다. 이때 균형을 맞추기 위해서는 크로스엔트로피 손실에 가중치를 10정도로 주고, MSE 손실에는 가중치를 0.25정도로 줘서 균형을 맞출 수 있습니다.
model.compile(optimizer='rmsprop',
loss=['mse', 'categorical_crossentropy', 'binary_crossentropy'],
loss_weights=[0.25, 1., 10.])
model.compile(optimizer='rmsprop',
loss={'age': 'mse',
'income': 'categorical_crossentropy',
'gender': 'binary_crossentropy'},
loss_weights={'age': 0.25,
'income': 1.,
'gender': 10.})
위 모델을 훈련하는 방법은 다중 입력 모델과 마찬가지로, 넘파이 배열의 리스트나 딕셔너리를 전달하여 훈련합니다.
model.fit(posts, [age_targets, income_targets, gender_targets],
epochs=10, batch_size=64)
model.fit(posts, {'age': age_targets,
'income': income_targets,
'gender': gender_targets},
epochs=10, batch_size=64)
층으로 구성된 비순환 유향 그래프
함수형 API를 사용하면 내부 토폴로지가 복잡한 네트워크도 만들 수 있습니다. 케라스의 신경망은 층으로 구현된 어떤 비순환 유향 그래프를 구현할 수 있습니다. 즉, 원형을 띨 수 없습니다. 텐서 x가 자기 자신을 출력하는 층의 입력이 될 수 없다는 것입니다. 만들 수 있는 루프는 순환 층의 내부에 있는 루프 뿐입니다.
가장 널리 사용되는 신경망 컴포넌트는 인셉션 모듈과 잔차 연결입니다.
인셉션 모듈
인셉션 모듈은 합성곱에서 인기 있는 네트워크 구조입니다. 영화 인셉션에서 꿈 속의 꿈처럼, 네트워크 안의 네트워크 구조를 갖고있습니다. 1x1 합성곱으로 시작해서 3x3 합성곱이 뒤따르고, 마지막에는 전체 출력이 합쳐집니다. 이런 구성은 네트워크가 공간 특성과 채널 방향의 특성을 따로 학습하도록 돕습니니다. 이 구조는 한번에 채널과 공간 방향의 특성을 모두 학습하는 것 보다 효과가 더 좋습니다. 더 복잡한 인셉션 모듈은 풀링 연산, 여러 가지 합성곱 사이즈를 사용합니다. 다음 그림은 인셉션V3에 있는 모듈입니다.

여기서 1x1 합성곱이 무슨 의미가 있나? 라고 생각할 수 있습니다. 1x1 합성곱은 공간 방향 특성은 학습을 하지 않고, 채널 방향 특성만 학습을 합니다. 입력의 채널이 공간 방향으로 상관관계가 크고, 채널 간에는 독립적이라고 가정하면 납득할 수 있을만한 전략입니다. 따라서 공간과 채널의 특성을 따로 학습할 수 있기 때문에 효과가 더 좋습니다. 그림으로 나타내면 다음과 같습니다.

함수형 API를 사용하여 위 인셉션 모듈을 구현하는 코드는 다음과 같습니다.
from keras import layers
branch_a = layers.Conv2D(128, 1,
activation='relu', strides=2)(x)
branch_b = layers.Conv2D(128, 1, activation='relu')(x)
branch_b = layers.Conv2D(128, 3, activation='relu', strides=2)(branch_b)
branch_c = layers.AveragePooling2D(3, strides=2)(x)
branch_c = layers.Conv2D(128, 3, activation='relu')(branch_c)
branch_d = layers.Conv2D(128, 1, activation='relu')(x)
branch_d = layers.Conv2D(128, 3, activation='relu')(branch_d)
branch_d = layers.Conv2D(128, 3, activation='relu', strides=2)(branch_d)
output = layer.concatenate(
[branch_a, branch_b, branch_c, branch_d], axis=-1)
인셉션 V3의 전체 구조는 keras.applications.inception_v3.InceptionV3에 준비되어 있으며, ImageNet 데이터셋을 사용하여 사전 훈련된 가중치를 포함하고 있습니다. 이와 비슷한 모델인 엑셉션(Xception)도 케라스의 어플리케이션 모듈에 포함되어 있으며, 엑셉션은 극단적인 인셉션(extreme inception)을 의미합니다.
엑셉션은 채널 방향의 학습과 공간 방향의 학습을 극단적으로 분리한다는 아이디어에 착안하여 인셉션 모듈을 깊이 분리별 합성곱으로 바꿉니다. 인셉션 모듈의 극한 형태로, 공간 특성과 채널 방향 특성을 완전히 분리합니다. 엑셉션은 파라미터 개수가 인셉션 V3와 거의 비슷하지만, 파라미터를 더 효율적으로 사용하기 때문에 실행 속도 및 정확도에서 더 나은 성능을 보여줍니다.

인셉션 모듈을 간단하게 나타내면 왼쪽 그림이고, 왼쪽 그림을 더 간단하게 나타낸 것이 오른쪽 그림입니다. 두 그림은 같은 구조입니다.
엑셉션 모듈은 아래 그림의 구조를 갖습니다.

잔차 연결
잔차 연결(residual connection)은 엑셉션을 포함하여 많은 네트워크 구조에서 사용하는 그래프 형태의 네트워크 컴포넌트 입니다. 이 구조는 대규모 딥러닝에서 자주 나타나는 그래이디언트 소실과 표현 병목(representational bottleneck)을 해결했습니다.
잔차 연결은 하위 층의 출력을 상위 층의 입력으로 사용합니다. 하위 층의 출력이 상위 층의 활성화 출력에 병합되는 것이 아니라, 더해집니다. 따라서 두 출력의 크기가 같아야 합니다. 입력 x가 4D 텐서라고 가정했을 때, 다음과 같은 식으로 구현합니다.
from keras import layers
x = ...
y = layers.Conv2D(128, 3, activation='relu', padding='same')(x)
y = layers.Conv2D(128, 3, activation='relu', padding='same')(y)
y = layers.Conv2D(128, 3, activation='relu', padding='same')(y)
y = layers.add([y, x])
만약 크기가 다르면 선형 변환을 사용하여 하위 층의 출력을 목표 층의 크기로 변환합니다.
from keras import layers
x = ...
y = layers.Conv2D(128, 3, activation='relu', padding='same')(x)
y = layers.Conv2D(128, 3, activation='relu', padding='same')(y)
y = layers.MaxPooling2D(2, strides=2)(y)
# y가 풀링으로 인해 크기가 줄었으므로, 원본 텐서 x도 1x1 합성곱을 사용하여 다운샘플링합니다.
residual = layers.Conv2D(128, 1, strides=2, padding='same')(x)
y = layers.add([y, residual])
층 가중치 공유
함수형 API의 기능 중 하나는 층 객체를 여러 번 사용할 수 있다는 점입니다. 층 객체를 두 번 호출하면 새로운 층 객체를 만드는 것이 아니라, 동일한 가중치를 재사용합니다. 이런 기능 때문에 공유 가지를 가진 모델을 만들 수 있습니다.
예를 들어, 두 문장 사이의 의미가 비슷한지 측정하는 모델이 있다고 가정해보겠습니다. 이 모델은 2개의 입력을 받고, 0과 1 사이의 점수를 출력합니다. 0에 가까울수록 관련이 없고, 1에 가까울수록 문장이 동일하거나 재구성되었다는 것을 의미합니다.
이런 문제에서는 두 입력 시퀀스가 바뀔 수 있습니다. 의미가 비슷하다는 것은 대칭적인 관계라는 뜻입니다. 즉, A에서 B에 대한 유사도는 B에서 A에 대한 유사도와 같습니다. 따라서 각 입력 문장을 처리하는 2개의 독립된 모델을 학습 할 필요는 없어보입니다. 대신 하나의 LSTM층으로 양 쪽을 모두 처리하는 것이 가능합니다. 이를 코드로 구현하면 다음과 같습니다.
from keras import layers
from keras import Input
from keras.models import Model
lstm = layers.LSTM(32)
left_input = Input(shape=(None, 128))
left_output = lstm(left_input)
right_input = Input(shape=(None, 128))
# 기존 층 객체를 호출하면 가중치가 재사용됩니다
right_output = lstm(right_input)
merged = layers.concatenate([left_output, right_output], axis=-1)
predictions = layers.Dense(1, activation='sigmoid')(merged)
# 최종적으로, 양 쪽 입력을 바탕으로 훈련됩니다.
model = Model([left_input, right_input], predicitions)
model.fit([left_data, right_data], targets)
층과 모델
함수형 API에서는 모델을 층처럼 사용할 수 있습니다. Sequential 클래스와 Model 클래스에 모두 적용되는데, 이는 입력 텐서로 모델을 호출해서 출력 텐서를 얻을 수 있다는 것입니다.
y = model(x)
모델에서 입력 텐서와 출력 텐서가 여러 개이면, 텐서의 리스트로 호출합니다.
y1, y2 = model([x1, x2)
이러면 모델의 가중치가 재사용됩니다. 층 객체든 모델 객체든 객체를 호출하는 것은 그 객체가 가진 가중치를 항상 재사용합니다.
이번에는 듀얼 카메라에서 입력을 받고, 각각 이미지를 처리하여 깊이를 감지하는 예시입니다. 이 때는 왼쪽 카메라와 오른쪽 카메라의 시각적 특징을 추출하기 위해 2개의 독립된 모델을 훈련할 필요가 없습니다. 두 입력에 저수준 처리 과정이 공유될 수 있습니다.
from keras import layers
from keras import applications
from keras import Input
xception_base = applications.Xception(weights=None, include_top=False)
left_input = Input(shape=(250, 250, 3))
right_input = Input(shape=(250, 250, 3))
left_features = xception_base(left_input)
right_features = xception_base(right_input)
merged_features = layers.concatenate([left_features, right_features], axis=-1)