[Deep Learning with Python] 5-2, 5-3 케라스 콜백과 텐서보드를 사용한 딥러닝 모델 검사와 모니터링, 모델 성능 최대로 끌어올리기
이번 포스트는 케라스 창시자에게 배우는 딥러닝(Deep Learning with Python)의 ch.7을 참고하였습니다.
이번 포스트를 읽기 전에, [Do it!] 시리즈를 먼저 읽는것을 권장합니다. 이 포스트에서는 [Do it!] 시리즈에 중복해서 나온 내용들을 많이 생략하였습니다.
이 책은 딥 러닝의 입문서로서는 적절하지 않다고 생각됩니다. 딥 러닝에 대한 어느정도 지식이 있고, 케라스의 사용방법에 대해 좀 더 자세히 알고 싶은 분께 권장합니다.
케라스 콜백과 텐서보드를 사용한 딥러닝 모델 검사와 모니터링
콜백을 사용하여 모델의 훈련 과정 제어하기
모델을 훈련할 때는 예상할 수 없는 것들이 많이 있습니다. 예를 들면, 최적의 모델을 위해 에포크가 얼마나 필요한지는 훈련하기 전에는 알 수 없으므로, 지금까지는 적절한 훈련 에포크를 알아보기 위해 충분한 에포크로 실험해보고, 그래프를 통해 확인했습니다. 이런 방법은 별로 효율적이지 못한 방법입니다.
더 좋은 방법은 검증 손실이 향상되지 않을 때 훈련을 멈추는 것입니다. 이는 케라스의 콜백을 사용해서 구현할 수 있습니다. 콜백은 fit() 메서드가 호출될 때 전달되는 객체입니다. 콜백을 사용하는 사례는 다음과 같습니다.
- 모델 체크포인트 저장 : 훈련하는 동안 어떤 지점에서 모델의 현재 가중치를 저장합니다.
- 조기 종료 : 검증 손실이 더이상 개선되지 않을 때, 최선의 결과를 저장하고, 훈련을 중지합니다.
- 하이퍼파라미터 동적 조정 : optimizer의 learning rate같은 파라미터를 훈련하는 동안 동적으로 조정합니다.
- 훈련과 검증 지표를 기록하거나 모델이 학습한 표현을 시각화 : 지금까지 훈련할 때 에포크마다 현재 훈련이 어떻게 진행되는지 보여주는 진행 표시줄을 의미합니다.
keras.callbacks 모듈에는 다음과 같은 내장 콜백이 있습니다.
- keras.callbacks.ModelCheckpoint
- keras.callbacks.EarlyStopping
- keras.callbacks.LearningRateScheduler
- keras.callbacks.ReduceLROnPlateau
- keras.callbacks.CSVLogger
이 외에도 여러 콜백이 있습니다.
ModelCheckpoint, EarlyStopping 콜백
EarlyStopping 콜백을 사용하면 정해진 에포크 이내에 모니터링하는 지표가 향상되지 않으면 훈련을 중지할 수 있습니다. 따라서 큰 값의 에포크로 훈련 후, 에포크를 다시 줄여서 훈련할 필요가 없습니다. 일반적으로 이 모델은 훈련하는동안 모델을 계속 저장해주는 ModelCheckpoint와 같이 사용하며, 지금까지 가장 좋은 모델만 저장할 수 있습니다.
import keras
callbacks_list = [kears.callbacks.EarlyStopping(monitor='val_acc',
patience=1,),
keras.callbacks.ModelCheckpoint(filepath='my_models.h5',
monitor='val_loss',
save_best_only=True)]
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
model.fit(x, y, epochs=10,
batch_size=32,
callbacks=callbacks_list,
validation_data=(x_val, y_val))
line4의 patience=1은 1에포크보다 더 길게, 즉 2에포크 동안 val_acc가 향상되지 않으면 훈련을 중지합니다.
ReduceLROnPlateau 콜백
이 콜백을 사용하면 검증 손실이 향상되지 않을 경우, 학습률을 작게 할 수 있습니다. 손실 곡선이 평탄할 때 학습률을 조절하면 지역 최솟값에서 효과적으로 빠져나올 수 있습니다.
callbacks_list = [keras.callbacks.ReduceLROnPlateau(monitor='val_loss',
factor=0.1,
patience=10)]
model.fit(x, y, epochs=10,
batch_size=32,
callbacks=callbacks_list,
validation_data=(x_val, y_val))
자신만의 콜백 만들기
훈련 도중에 내장 콜백이 제공하지 않는 특수한 행동이 필요하면 우리가 필요한 대로 콜백을 만들 수 있습니다. keras.callbacks.Callback 클래스를 상속받아서 구현할 수 있습니다. 그다음, 훈련하는 동안 호출될 여러 지점을 나타내기 위해 약속된 다음 메서드를 구현합니다.
on_epoch_begin - 각 에포크가 시작할 때 호출
on_epoch_end - 각 에포크가 끝날 때 호출
on_batch_begin - 각 배치 처리가 시작되기 전에 호출
on_batch_end - 각 배치 처리가 끝난 후 호출
on_train_begin - 훈련이 시작될 때 호출
on_train_end - 훈련이 끝날 때 호출
이 메서드들은 모두 logs 매개변수화 함께 호출됩니다. 또한, 콜백은 다음 속성을 참조할 수 있습니다.
- self.model : 콜백을 호출하는 객체
- self.validation_data : fit() 메서드에 전달된 검증 데이터
다음은 매 에포크의 끝에서 검증 세트의 첫 번째 샘플을 사용해서 모델의 모든 층의 활성화 출력을 계산 후, 파일로 저장하는 콜백의 예 입니다.
import keras
import numpy as np
class ActivationLogger(keras.callbacks.Callback):
def set_model(self, model):
self.model = model
layer_outputs = [layer.output for layer in model.layers]
self.activations_model = keras.models.Model(model.input,
layer_outputs)
def on_epoch_end(self, epoch, logs=None):
if self.validation_data is None:
raise RuntimeError('Requires validation data.')
# 검증 데이터의 첫 번째 샘플을 가져옵니다
validation_sample = self.validation_data[0][0:1]
activations = self.activations_model.predict(validation_sample)
f = open('activations_at_epoch_' + str(epoch) + '.npz', 'wb')
np.savez(f, activations)
f.close()
텐서보드 : 텐서플로의 시각화 프레임워크
텐서보드는 텐서플로 백엔드로 케라스를 설정해야 케라스 모델에서 사용할 수 있습니다.
텐서보드의 핵심 목적은 훈련 중 모델 내부에서 일어나는 일들을 시각적으로 모니터링할 수 있도록 돕는 것입니다. 모델의 최종 손실 외에 더 많은 정보를 모니터링하면 모델 작동에 대해 더 명확하게 알 수 있으며, 따라서 모델을 더 빠르게 개선할 수도 있습니다. 텐서보드가 제공하는 기능들은 다음과 같습니다.
- 훈련하는 동안 측정 지표를 시각적으로 모니터링하기
- 모델 구조를 시각화하기
- 활성화 출력과 그래이디언트의 히스토그램 그리기
- 3D로 임베딩 표현하기
IMDB 감성 분선 문제를 위한 간단한 1D 합성곱 예제를 통해서 위의 기능들을 확인해보겠습니다.
import keras
from keras import layers
from keras.datasets import imdb
from keras.preprocessing import sequence
max_features = 2000
max_len = 500
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
x_train = sequence.pad_sequences(x_train, maxlen=max_len)
x_test = sequence.pad_sequences(x_test, maxlen=max_len)
model = keras.models.Sequential()
model.add(layers.Embedding(max_features, 128,
input_length=max_len,
name='embed'))
model.add(layers.Conv1D(32, 7, activation='relu'))
model.add(layers.MaxPooling1D(5))
model.add(layers.Conv1D(32, 7, activation='relu'))
model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(1))
model.summary()
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
현재 작업 경로에 'my_log_dir'이라는 디렉토리를 만들고, 다음 코드를 실행해봅니다.
callbacks = [keras.callbacks.TensorBoard(log_dir='my_log_dir', # 로그 파일 디렉토리
histogram_freq=1, # 1 에포크마다 활성화 출력 기록
embeddings_freq=1,)] # 1 에포크마다 임베딩 데이터 기록
history = model.fit(x_train, y_train,
epochs=20,
batch_size=128,
validation_split=0.2,
callbacks=callbacks)
그리고, 터미널 창에서 다음 명령을 실행합니다. 리눅스 환경인 경우 터미널 창에 입력하면 되고, 아나콘다의 경우 anaconda powershell에서 입력하면 됩니다.
$ tensorboard --logdir=my_log_dir
그 후, 인터넷 브라우저에서 http://localhost:6006을 입력하면 훈련 결과를 확인할 수 있습니다. 위 모델의 훈련은 거의 시작하자마자 바로 과대적합되는 결과를 보여줍니다.

GRAPH 탭에 들어가면 다음과 같이 케라스 모델을 구성하는 저수준 텐서플로 연산의 그래프를 볼 수 있습니다.

예상보다 훨씬 복잡합니다. 케라스에서 만든 모델은 간단해 보이지만, 실제로는 상당히 복잡한 그래프 구조가 만들어집니다. 이 것이 케라스를 사용하는 이유입니다. 케라스를 사용하면 이렇게 복잡한 구조를 간단하게 구현할 수 있습니다.
keras.utils.plot_model 유틸리티는 위 그래프를 깔끔하게 그려줍니다. 이 유틸리티를 사용하기 위해서는 pydot, pydot-ng, graphviz 라이브러리가 필요합니다. pip 명령으로 설치하면 됩니다. 윈도우에서 아나콘다를 사용하는 경우, graphviz는 다음 순서에 따라 설치합니다.
1. https://www2.graphviz.org/Packages/stable/windows/10/cmake/Release/x64/ 에서 graphviz 설치. 설치 과정에서 후 환경변수 추가 옵션 선택
2. 아나콘다 power shell을 실행하고, conda install python-graphviz 입력
from keras.utils import plot_model
plot_model(model, to_file='model.png')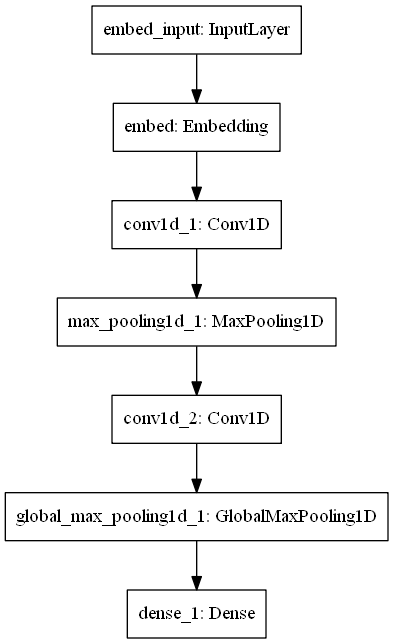
다음과 같이 그래프에 크기 정보를 입력할 수 있습니다.
from keras.utils import plot_model
plot_model(model, show_shapes=True, to_file='model_.png')
모델 성능 최대로 끌어올리기
고급 구조 패턴
이전에 인셉션 구조 및 잔차 연결이라는 중요한 디자인 패턴을 소개했습니다. 이 외에도 또 알아야 할 디자인 패턴이 있는데, 정규화와 깊이별 분리 합성곱입니다.
배치 정규화
정규화(normalization)은 머신 러닝 모델에 입력으로 사용되는 샘플들을 균일하게 만드는 방법입니다. 가장 일반적인 형태는 평균을 빼고, 표준 편차로 나누는 것입니다.
이전 예제는 모델에 데이터를 주입하기 전에 정규화 했지만, 데이터 정규화는 네트워크에서 일어나는 모든 변환 후에도 고려되어야 합니다. Dense나 Conv2D 층에 사용되는 입력 데이터가 정규화된 데이터라고 해도, 그 출력도 평균이 0이고 분산이 1인 분포를 가질 것이라 기대하기는 어렵습니다.
배치 정규화는 훈련하는 동안 평균과 분산이 바뀌더라도 이에 적응하여 데이터를 정규화합니다. 훈련 중 사용된 배치 데이터의 평균과 분산에 대한 지수 이동 평균을 내부에 유지합니다. 배치 정규화는 잔차 연결처럼 그래이디언트의 전파를 도와주므로, 더 깊은 네트워크를 구성할 수 있습니다. 케라스에서는 BatchNormalization 클래스로 제공하며, ResNet50, Inception V3, Xception 등 고급 합성곱 신경망 구조는 배치 정규화 층을 많이 사용합니다.
BatchNormalization층은 보통 합성곱이나 완전 연결층 다음에 사용합니다.
conv_model.add(layers.Conv2D(32, 3, activation='relu'))
conv_model.add(layers.BatchNormalization())
dense_model.add(layers.Dense(32, activation='relu'))
dense_model.add(layers.BatchNormalization())
BatchNormalization 클래스는 정규화 할 특성 축을 지정할 수 있는 axis 매개변수가 있는데, 기본값은 -1입니다. 만약 데이터 포맷이 channel_first인 경우에는 axis=1로 지정해줘야 합니다.
깊이별 분리 합성곱
깊이별 분리 합성곱은 Conv2D보다 더 가볍도, 모델의 성능을 더 높일 수 있습니다. 이 층은 각 채널별로 공간 방향의 합성곱을 수행하고, 1x1 합성곱을 통해 출력 채널을 합칩니다. 이는 이전에 언급했던 Xception의 구조의 기반입니다.

이는 공간 특성의 학습과 채널 특성의 학습을 분리하는 효과를 내고, 모델 파라미터와 연산의 수를 크게 줄이기 때문에 더 작고 빠른 모델을 만듭니다.
이 구조의 장점은 제한된 데이터로 작은 모델을 처음부터 훈련시킬 때 특히 더 효과를 보인다는 것입니다. 다음은 작은 데이터셋에서 이미지 분류 문제를 위한 간단한 깊이별 분리 합성곱 신경망을 만드는 예입니다.
from keras.models import Sequential, Model
from keras import layers
height = 64
width = 64
channels = 3
num_classes = 10
model = Sequential()
model.add(layers.SeparableConv2D(32, 3,
activation='relu',
input_shape=(height, width, channels,)))
model.add(layers.SeparableConv2D(64, 3, activation='relu'))
model.add(layers.MaxPooling2D(2))
model.add(layers.SeparableConv2D(64, 3, activation='relu'))
model.add(layers.SeparableConv2D(128, 3, activation='relu'))
model.add(layers.MaxPooling2D(2))
model.add(layers.SeparableConv2D(64, 3, activation='relu'))
model.add(layers.SeparableConv2D(128, 3, activation='relu'))
model.add(layers.GlobalAveragePooling2D())
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(num_classes, activation='softmax'))
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
model.summary()

하이퍼파라미터 최적화
딥러닝 모델을 만들 때, 결정해야 하는 하이퍼 파라미터는 다음과 같습니다.
- 얼마나 많은 층을 쌓아야 하는가?
- 층 마다 몇 개의 유닛 또는 필터를 둬야 하는가?
- 활성화 함수는 어떤 함수를 사용해야 하는가?
- 어떤 층 뒤에 BatchNormalization을 사용해야 하는가?
- 드롭 아웃의 비율은?
- 그 외 여러가지
경험이 많은 엔지니어들은 하이퍼파라미터에 따라 작동하는 것과 작동하지 않는 것에 대한 직관을 갖고 있지만, 공식적인 규칙은 없습니다. 머신 러닝 모델을 만들 때, 대부분의 시간은 옵션을 수정하고 모델을 반복적으로 훈련하여 선택 사항을 개선하기 위해 사용됩니다. 하지만 사람이 하루종일 이 훈련을 보면서 하이퍼파라미터를 튜닝 하는 것은 비효율적인 일이므로, 이는 컴퓨터한테 맡기는 것이 훨씬 낫습니다.
전형적인 하이퍼파라미터 최적화 과정은 다음과 같습니다.
1. 일련의 하이퍼파라미터를 (자동으로) 선택
2. 선택된 하이퍼파라미터로 모델 생성
3. 학습하고, 검증 데이터에서 최종 성능 측정
4. 하이퍼파라미터를 다시 선택
5. 위 과정 반복
6. 마지막으로, 테스트 데이터를 사용하여 성능 측정
주어진 하이퍼파라미터에서 얻은 검증 성능을 사용하여 그 다음 훈련에서 사용할 하이퍼파라미터를 선택하는 알고리즘에는 베이지안 최적화(bayesian optimization), 유전 알고리즘(genetic algorithms), 랜덤 탐색(random search) 등이 있습니다.
하이퍼파라미터를 튜닝하는 것은 꽤 어려운 일입니다. 그 이유는 다음과 같습니다.
- 피드백 신호를 계산하기 위해서는 비용이 매우 많이 듭니다. 피드백을 할 때마다 새로운 모델을 만들고, 훈련을 처음부터 다시 시작해야합니다.
- 하이퍼파라미터 공간은 연속적이지 않고, 따라서 미분 가능하지 않으므로 경사 하강법을 사용할 수 없습니다. 따라서 그래이디언트 프리(gradient free) 최적화 기법을 사용해야 합니다.
모델 앙상블
앙상블은 여러 개의 다른 모델의 예측을 합쳐서 더 나은 예측을 만듭니다. 뛰어난 단일 모델보다는 그보다 모자란 모델 여러 개를 사용하는 것이 성능이 더 좋다는 의미입니다.
앙상블은 다른 종류의 모델이 독립적으로 훈련되어있으며, 각기 다른 장점을 가지고 있다는 가정을 기반으로 합니다. 각 모델은 예측을 위해 조금씩 다른 측면을 바라봅니다. 데이터의 전체를 보는 것이 아니라, 부분 특징을 보는 것입니다.
장님 여러명이 코끼리의 일부분을 만지는 우화는 다들 들어봤을 것이라고 생각합니다. 여기 나오는 장님들이 훈련 데이터의 매니폴드를 이해하려는 머신 러닝이라고 보면 됩니다. 각자의 가정(각 모델의 구조와 랜덤한 가중치 초기화)을 사용하여 각자의 관점으로 데이터를 이해합니다. 각 모델의 출력은 데이터의 일부분에는 맞는 정답이지만 완전한 정답은 아닙니다. 하지만 이 관점들을 모으면 데이터를 훨씬 정확하게 묘사할 수 있습니다.
분류 모델의 예를 들어보겠습니다. 가장 간단한 방법은 각 모델의 예측을 평균 내는 것입니다.
preds_a = model_a.predict(x_val)
preds_b = model_b.predict(x_val)
preds_c = model_c.predict(x_val)
preds_d = model_d.predict(x_val)
final_preds = 0.25*(preds_a + preds_b + preds_c + preds_d)이 방식은 각 분류기들이 비슷한 성능을 낼 때 잘 작동합니다. 분류기들 중 하나가 성능이 너무 나쁘면 최종 예측은 앙상블에 있는 가장 좋은 분류기보다 좋지 않을 수도 있습니다.
분류기를 앙상블하는 좋은 방법은 가중치를 사용하여 가중 평균하는 것입니다. 좋은 분류기의 성능이 좋을수록 높은 가중치를 두고, 나쁠수록 낮은 가중치를 두는 것입니다. 좋은 가중치를 찾기 위해 랜덤 탐색이나 넬더-미드(Nelder_mead)방법 같은 최적화 알고리즘을 사용할 수도 있습니다.
preds_a = model_a.predict(x_val)
preds_b = model_b.predict(x_val)
preds_c = model_c.predict(x_val)
preds_d = model_d.predict(x_val)
final_preds = 0.5*preds_a + 0.25*preds_b + 0.1*preds_c + 0.15*reds_d
이 외에도 예측의 지수 값을 평균하는 등의 여러 변종이 있습니다. 일반적으로는 검증 데이터에서 찾은 최적의 가중치로 단순하게 가중 평균하는 방법이 좋은 기본값입니다.
앙상블의 핵심은 분류기의 다양성입니다. 만약 장님들이 모두 같은 부분만 만졌다면, 예를 들어 모두 코만 만졌다면 장님들은 모두 코끼리는 기다란 뱀 같은 동물이라는데에 동의했을 것입니다. 즉, 머신 러닝에서 모든 모델을이 같은 방향으로 편향되어있다면, 앙상블은 동일한 편향을 유지할 것이고, 서로 다른 방향으로 편향되어 있다면 이 편향은 서로 상쇄돼고, 앙상블이 더 좋은 결과를 보일 것입니다.
따라서, 우리는 최대한 다르면서 좋은 모델들을 앙상블해야 합니다. 일반적으로 매우 다른 구조를 가지거나 다른 종류의 머신 러닝 방법을 말합니다. 같은 네트워크에서 가중치만 랜덤으로 초기화해서 따로 여러 번 훈련하여 앙상블하는 것은 별로 도움이 되지 않습니다.
실전에서 잘 동작하는 방법 중 하나는 트리 기반 모델(랜덤포레스트나 그래이디언트 부스팅)이나 심층 신경망을 앙상블하는 것입니다. 앙상블을 할 때는 모델중에 눈에 띄게 나쁜 모델이 있다고 해도, 이 모델이 전체 성능을 크게 향상시킬 수도 있습니다. 그 모델의 성능이 낮다고 할지라도, 다른 모델들이 가지지 못한 정보를 제공할 수 있기 때문입니다. 앙상블에서 중요한 점은 최상의 모델이 얼마나 좋은지가 아니라 앙상블의 후보 모델이 얼마나 다양한지가 더 중요합니다.