Deep Sensor Fusion for Real-Time Odometry Estimation
이 글은 Michelle Valente, Cyril Joly, Arnaud de La Fortelle의 Deep Sensor Fusion for Real-Time Odometry Estimation 의 일부를 번역한 글입니다.
원본은 https://arxiv.org/pdf/1908.00524.pdf 입니다.
Abstract-
카메라와 2D 레이저 스캐너는 낮은 비용, 가벼운 가중치와 정확한 솔루션으로 많은 로봇 내비게이션 작업에 잘 맞는 조합입니다. 하지만, 정확한 데이터 퓨전은 센서들 사이의 rigid body transform의 정확한 캘리브레이션(calibration)에 의존합니다. 이 논문에서는 모노 카메라(mono camera)와 2D 레이저 스캐너의 데이터를 퓨전하여 오도메트리를 추정하기 위해 CNNs을 사용하는 프레임워크를 보여줍니다. CNNs을 사용하면 두 센서들의 특징들을 추출할 수 있을 뿐 아니라, 데이터를 퓨전하고 매칭하기 위해 두 센서 사이의 캘리브레이션을 계산할 필요도 없습니다. 이 논문에서는 오도메트리 추정값을 두 개의 연속적인 프레임 사이의 정확한 회전과 병진(translation)값을 찾기 위해 순서를 분류하는 문제로 변환하였습니다. 실제 도로에서의 데이터셋은 이 퓨전 네트워크가 실시간으로 동작하며, 두 가지 다른 유형의 데이터 정보를 퓨전하는 방법을 학습함으로써 단일 센서의 주행 거리 추정을 향상시킬 수 있음을 보여줍니다.
1. Introduction
지능형 차량의 self-localization은 여전히 자율 주행 개발을 위해 현재 진행중인 도전적인 작업입니다. 신뢰할만한 수준의 위치 추정은 지능형 차량이 다른 차량을 추월하거나 주행 경로를 간단하게 정의하는 등의 중요한 결정을 할 수 있도록 하기 위해 필요합니다. 이러한 작업 중에는 SLAM이라고 알려져 있는, 이전에 주행해보지 않았던 현재 환경을 맵핑하고 로봇의 위치를 추정하기 위해 사용하는 방법이 있습니다. 이런 목적으로 카메라, 레이저 스캐너, 레이더 등이 사용될 수도 있습니다. 각 센서들은 고유의 장단점이 있고, 이런 이유때문에 단일 센서만 사용되는 경우는 거의 없습니다. 따라서, 여러 작업의 정확도를 위해서는 여러 센서들을 퓨전하는 것이 필요합니다. 센서 퓨전에 있어서 주된 어려움 중 하나는 공통적인 데이터 형식(data format)을 갖도록 하는 것과, 다른 센서들 사이의 정확한 캘리브레이션을 갖도록 하는것입니다.
자율주행 연구를 위해 3차원 레이저 스캐너를 사용하는 것은 매우 인기있는 방법이지만 이 센서는 가격이 매우 비싸고, 이는 미래에도 합리적인 가격으로 자율주행 차량을 제조하는데 있어서 문제가 될 것입니다. 더군다나, 3차원 레이저 스캐너에 의해 수집된 데이터는 용량이 매우 크기 때문에 이를 실시간으로 처리하기 위해서는 엄청난 컴퓨팅 자원이 필요하게 됩니다. 이를 고려해서, 이 논문에서는 가격이 저렴한 2차원 레이저 스캐너를 사용한 솔루션에 초점을 맞춥니다. 하지만 2차원 레이저 스캔은 각각의 스캔에서 단지 주변 환경의 일부분만을 감지하기 때문에, 이 센서에만 의존하는 것은 일부 상황에서는 사용되기 어려울 수 있습니다. 따라서, 이 문제를 해결하기 위해서 2차원 레이저 스캐너와 모노 카메라를 사용하는 방법을 제안합니다. 이 방법은 주변 환경에 대해 더 많은 정보를 감지할 수 있고, 위치추정 방법의 정확도를 증가시킬 수 있습니다.
2018년에 딥 러닝은 자율 주행 분야의 주목을 끌었습니다. 가장 일반적인 응용 분야는 카메라나 레이저 스캐너를 사용해서 장애물 감지나 분류 문제같은 작업을 하는 것이었습니다. 이런 작업들은 주변 환경을 이해하고, 맵핑하는 분야에서 주로 사용되었습니다. 하지만, 차량의 위치 추정과 다른 센서들을 퓨전하는 것은 아직 머신 러닝 분야에서 충분히 깊게 연구되지 않았습니다. 이 목적으로 인공 신경망을 사용하는 것은 작업을 빠르게 해줄 뿐 아니라, 센서들 사이의 정확한 캘리브레이션의 필요성을 제거해줄 수도 있습니다.
이를 고려하여, 이 논문에서는 두 가지 다른 센서인 2D 레이저 스캐너와 모노 카메라의 특징을 추출하고, 이를 순차적으로 퓨전하여 차량의 오도메트리를 추정하기 위해 CNNs을 사용하는 딥 러닝 접근법을 제안합니다. 제안된 접근법의 구조는 그림 1과 같습니다.

본 논문에서는 오도메트리 추정 회귀 문제를 네트워크로 훈련이 가능하게 하는 순서 분류 문제로 변환하는 방법을 소개합니다. 이 방법은 실시간으로 실행될 수 있고, 실제 도로 주행 시나리오에서 테스트된 결과는 다른 딥 러닝 접근법과의 경쟁력 있는 결과를 보여줍니다.
2. Related Work
딥 러닝의 응용 분야는 카메라 이미지를 이용해 장애물 감지나 분류 문제 같은 작업에서 놀라운 결과들을 보여주었습니다. 이런 결과들을 얻기 위해, 우리는 많은 양의 데이터셋을 사용할 수 있게 되었습니다. 지능형 차량의 맥락에서, 맵핑[5], 경로 예측[4], 제어[7], end-to-end 접근[6]과 같이 다른 분야에서 흥미로운 결과들이 나왔습니다.
이와 동시에, 로봇 시스템 분야에서 매우 도전적인 문제인 위치 추정 분야에서는 아직 딥 러닝 방법을 사용한 충분한 연구가 이루어지지 않았습니다. 가장 흔한 접근법은 카메라 이미지를 사용해서 오도메트리를 추정하는 것입니다. 이 방법은 클래식한 방법인 Visual Odometry(VO)[9][10]의 영향을 받았으며, 이 방법은 이미지 시퀀스로부터 기하학적 제약을 찾는 것을 통해 카메라의 움직임을 추정하는 것입니다. 이 목적으로 머신 러닝을 사용하는 것은 도전적인 환경과(challenging environment) 카메라 파라미터를 설정하는 것에 대한 어려움이 있습니다. 처음 제안된 방법은 PoseNet[11]인데, 이는 RGB 이미지만을 사용하여 6자유도의 pose를 추정하기 위해 CNNs를 사용합니다. 좀 더 최근에는 Wang이 소개한 DeepVO[12] 이 있는데, 이는 같은 RCNNs를 사용합니다. 이 외에도 UndeepVO[13] 또한 제안하였는데, 이는 monocular camera의 pose를 추정하기 위해 비지도학습을 사용합니다. 하지만, 아직까지는 전통적인 VO 방법이 지금까지 발표된 딥 러닝 기법보다 정확도가 더 좋습니다.
레이저 스캐너는 정확도가 높기 때문에 로봇의 pose estimation을 위해 인기가 있습니다. 이 문제를 위한 클래식한 방법은 Iterative Closet Point(ICP)라고 하는 방법인데, 이는 두 개의 포인트 클라우드를 매칭하고, 이 클라우드 사이의 변환(transformation)을 추정합니다. 이 때문에 더 강력하고(robust) 복잡한 알고리즘들이 같은 목표를 위해 발표되었습니다. LOAM[15]는 두 개의 다른 알고리즘을 병렬로 실행하여 높은 정확도를 갖고 실시간 처리가 가능하기 때문에 현재 가장 인기있는 방법 중 하나입니다.
이 목적으로 레이저 스캐너를 사용하여 딥 러닝 기술에 적용하는 것은 아직 자료가 별로 많지 않습니다. Nicolai 등은 처음으로 3D 레이저 스캐너 데이터를 사용해 CNNs로 오도메트리를 추정하는 방법을 제안하였습니다[16]. 하지만 이는 여전히 state-of-the-art san matching method의 효율성에 비하면 별로 경쟁력이 있지는 않습니다. Velas 등은 3D 레이저 스캐너 뿐 아니라 IMU 데이터까지 사용하였으며[18], 이는 더 높은 정확도를 보여주었고, LOAM같은 state-of-the-are methods에 근접한 성능을 보여주었습니다. 하지만, 병진(translation)에 대해서는 정확했지만, 회전(rotation)에 대해서는 충분히 정확한 예측을 하지 못했습니다. 이 결과들을 고려하면, 앞의 연구원들은 그들의 방법이 병진 운동을 추정할 수 있고, 회전 운동을 추정하기 위해 IMU도 사용될 수 있다는 것을 제안합니다. 하지만 다른 단점이 있는데, KITTI benchmark에 따르면 CNNs을 사용한 방법은 LOAM보다 느리다고 합니다.
3D 레이저 스캐너 대신 2D 레이저 스캐너를 사용하는 것은 미래의 지능형 자동차의 가격과 요구되는 컴퓨팅 파워를 매우 줄여줄 수 있습니다. 최근 몇 연구원들은 Recurrent Convolutional Neural Networks(RCNNs)로 단지 2D 레이저 스캐너 데이터만을 사용하여 오도메트리를 추정하는 방법을 제안하였습니다[19]. 이 방법은 아주 빠른 시간 내로 결과가 나오는 것을 보여주었습니다. 하지만, 이 접근법이 직면한 중요한 문제점 중 하나는, 몇몇 어려운 환경에서는 2D 레이저 스캐너 데이터로는 많은 장애물을 감지할 수 없기 때문에 부정확한 결과를 보여준다는 것입니다. 이를 고려해서, 본 논문에서는 모노 카메라와 2D 레이저 스캐너를 퓨전하여 CNNs만을 사용해서 개선된 오도메트리 추정을 하는 방법을 제안합니다.
레이저 스캐너와 카메라를 퓨전하는 것은 물체 인식과 모바일 로봇 내비게이션 문제에서는 흔하게 사용됩니다[20][21]. 센서 퓨전을 사용한 딥 러닝은 아직 연구가 충분히 이루어지지 않았습니다. 현재 센서 퓨전을 사용한 대부분의 딥 러닝 솔루션들은 [22]와 같이 물체의 bounding boxes를 예측하기 위한 카메라 이미지와 3D 레이저 스캐너를 퓨전한 물체 감지에 기반합니다. 센서 퓨전을 [23]과 같이 입력은 다른 센서들의 데이터이고, 출력은 바로 로봇의 조향 명령이 나오게 하는 end-to-end learning 방식에 사용하는 방법도 있습니다.
본 논문에서는 2D 레이저 스캐너와 카메라를 사용하여 오도메트리를 추정하는 방식을 제안합니다. 제안된 네트워크는 실시간 처리가 가능하며, 단일 센서만 사용할 때 생기는 문제점을 극복할 수 있습니다. 또한 오도메트리 회귀 문제를 순서 분류(ordinal classification)이라고 하는, 더 간단한 binary classification subproblem으로 변환하는 방법도 제안합니다.
3. Method
제안된 접근법은 카메라 이미지와 레이저 스캐너의 시퀀스 사이의 변환(transformation)을 추정하는 것에 의해 차량의 변위를 찾는 것으로 구성됩니다. 한 번의 관측은 1회전 시 360º로 회전하며 얻은 레이저 스캐너와 하나의 카메라 데이터로 이루어지며, 이와 같은 두 개의 연속적인 관측을 사용하여 네트워크가 변환 $T = [\Delta d, \Delta\theta]$을 예측합니다. 여기서, $\Delta d$와 $\Delta \theta$는 두 개의 연속적인 레이저 스캔 데이터 $(s_{t-1}, s_t)$와 카메라 데이터 $(c_{t-1}, c_t)$ 사이의 travel distance와 orientation을 나타냅니다. 그러므로, 최종 목표는 최적 함수 $g(.)$를 학습하는 것인데, 이 함수는 $(s_{t-1}, s_t)$와 $(c_{t-1}, c_t)$의 퓨전을 시간 $t$에서 $T$로 맵핑합니다. 즉,
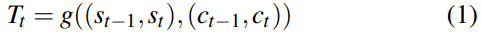
한 번 이 파라미터들을 학습하면, 우리는 시간 $t$에서의 차량의 2차원 pose $(x_t, y_t, \theta _t)$를 다음과 같이 얻을 수 있습니다.

이런 방식으로, 우리는 차량의 local pose를 누적할 수 있고, 이에 따라 시간 $t$에서 차량의 global position을 추정할 수 있습니다. 하지만 이 알고리즘은 어떤 종류의 loop clousre도 수행하지 않기 때문에 오차 또한 누적될 수 있고, 이는 차량의 위치 추정 정확도를 떨어뜨립니다. 하지만 이 논문에서의 주된 목표는 CNNs를 통해 카메라와 레이저 스캐너 데이터의 연속적인 두 프레임 사이의 오도메트리 추정이 가능하다는 것을 보여서, 인공 신경망을 통해 두 센서의 퓨전이 가능하다는 것을 입증하는 것입니다.
A. Data Pre-Processing
두 센서로부터 들어온 raw data는 인공 신경망의 입력으로 사용되기 전에 전처리되어야 합니다. 레이저 스캐너의 경우, [19]와 같이 레이저 포인트의 집합을 1차원 벡터로 인코딩합니다. 이 벡터는 raw scan을 해상도 0.1º의 bins으로 binning하는 것에 의해 만들어집니다. 많은 점들이 같은 bin으로 떨어질 수 있기 때문에, 평균 depth 값을 계산해야합니다. 마지막으로, 360º 범위의 모든 bins를 고려하여, 이 depth값들을 3601 크기의 벡터에 저장합니다. 이때 가능한 각각의 bin angle average depth는 그 벡터의 요소로 표시됩니다.
두 개의 레이저 스캔 데이터가 1D 벡터들로 인코딩된 후, 레이저 스캐너 네트워크의 입력을 만들기 위해 이 벡터들을 concatenate합니다. 이 아이디어는 크기 (2, 3601)사이즈의 이미지를 만드는 것이라고 볼 수 있습니다. 이는 standard convolutional layers가 주변 환경을 측정한 센서 데이터로부터 특징을 추출할 수 있게 해줍니다.
카메라 데이터의 경우에는 컴퓨팅 시간을 줄이기 위해 크기만 줄여줍니다. 여러 사이즈들을 테스트해봤지만 정확도에는 별 영향이 없었고, 실행 속도에는 영향이 있었습니다. 실험 결과, 정확도와 속도를 고려하여 가장 적절한 사이즈는 (416, 128)이었습니다. 이미지의 크기를 조절하고 나서, 획득한 두 카메라 이미지를 나타내는 텐서의 형태를 만들기 위해 두 개의 연속적인 이미지를 레이저 스캐너와 같은 방식으로 쌓습니다. 이 포맷은 CNNs가 특징을 추출할 수 있도록 두 개의 이미지를 같은 시퀀스에 넣을 수 있게 해줍니다.
B. Network Architecture

그림 2는 제안된 네트워크의 구조를 보여줍니다. 입력은 이전 섹션에서 설명했듯이 두 센서로부터 얻어진, pre-processed raw data입니다. 입력 층을 제외한 나머지 네트워크는 세 부분으로 분리되는데, 레이저 스캐너를 사용하는 CNN-Laser, CNN-Cam, fusion으로 나뉩니다.
1) CNN-Laser : 전처리된 두 개의 레이저 스캔 데이터는 크기가 3601인 1차원 벡터로 표현되며, 이 벡터들은 네트워크의 입력 텐서를 만들기 위해 concatenate됩니다. 순차적으로, 그 텐서는 획득된 두 데이터 사이의 특징들을 학습하기 위해 1차원 합성곱층과(1D convolutional layer) 평균 풀링 층(average pooling layer)의 입력으로 사용됩니다. 이 논문에서는 [19]와 같은 CNN configuration을 사용합니다. 이는 6개의 1차원 합성곱층으로 이루어져 있으며, 각 층의 활성화 함수는 ReLU 함수를 사용합니다. 두 개의 합성곱층 사이에는 계산 복잡도를 줄이기 위해 한 개의 평균 풀링 층이 들어갑니다. [19]와 다른 점은 추가적인 layer인데, 이는 CNNs의 시퀀스 이후에 있는 linear 층인데, 이는 데이터 fusion 이전에 텐서의 크기를 줄이기 위해 사용합니다. 목표는 위 네트워크의 센서 fusion 부분에 두 센서로부터 같은 양의 정보를 입력으로 사용하는 것입니다.
2) CNN-Cam : 카메라 네트워크의 configuration은 DeepVO[12]에 의해 제안된 RCNN에서 CNN부분입니다. 하지만, 이 논문에서는 전처리 부분에서 설명했던 더 작은 입력을 사용합니다. CNN-Laser와 같은 방식으로, fusion 이전에 텐서의 크기를 줄이기 위해 선형 층을 추가합니다. 그러므로, 입력은 두 개의 raw camera images이고, CNN-Laser에서 감지된 특징과 fusion하기 위해서 CNNs시퀀스에 의해 추출되고, 크기가 줄어든 결과가 출력으로 나옵니다.
3) Fusion : 이전에 설명한 CNNs를 사용하여 연속적인 레이저 스캐너와 카메라 이미지 데이터로부터 특징을 추출한 다음, 로봇의 pose를 추정하기 위해 두 결과를 concatenate합니다. concatenated된 특징들은 두 개의 다른 선형 레이어 층의 입력으로 사용됩니다. 본 논문에서는 같은 선형 층에서 병진과 회전 결과를 추정해봤지만, 둘을 분리하는 것이 더 나은 결과를 보임을 확인하였습니다. 또한, 과대 적합을 피하기 위해 두 선형 층에는 드롭아웃 층을 추가하였습니다.
C. Training
네트워크의 훈련은 두 단계로 이루어집니다. 먼저, 최적의 가능한 가중치를 구하기 위해 단일 센서 CNNs를 따로 훈련합니다. 이를 위해 본 논문에서는 이 네트워크들을 두 개의 분리된 선형 레이어 층, 즉 회전 추정하기 위한 레이어와 병진을 추정하기 위한 레이어로 연결합니다. 이 작업 이후, 사전에 훈련된 CNNs를 네트워크의 fusion부분에 연결하여 최종 훈련 스텝을 진행합니다.
[19]에서는 CNN 네트워크가 회전을 분류 작업으로 reformulate하고, 이를 병진의 회귀에 대한 작업으로도 적용하면 더 나은 결과를 얻을 수 있다는 것을 보여줍니다. 이는 두 프레임 사이에서 회전각에 대한 모든 가능한 변수를 고려하는 것인데, 예를 들어 ±5.6º이내에서 0.1º의 해상도로 회전한다고 할 때, 112개의 클래스로 분류하는 것입니다. 이 작업에서는 회전값을 추정하는 것을 분류 문제로서 다룰 수 있을 뿐 아니라, 병진 또한 이런 방식으로 훈련이 가능하도록 합니다. 본 논문에서는 KITTI데이터셋에서 가능한 모든 시퀀스를 관찰했는데, 두 프레임 사이의 최대 병진값은 약 2.6미터이고, 최소치는 0미터였습니다. 따라서, 이 인터벌에서 0.01미터의 해상도를 사용하면 이를 270개의 클래스로 나눌 수 있습니다. 실험 결과는 네트워크가 수렴하기는 더 쉬우나 정확도는 떨어지지 않는다는 것을 보여줍니다.
회전과 병진을 분류 문제로 변환할 때의 가장 큰 문제점은, 네트워크가 데이터에 대한 순서를 학습하지 않는다는 것입니다. 이는 머신러닝 기법에서 분류 문제는 보통 클래스에 순서가 없다고 가정하기 때문입니다. 예를 들어, 각도 2도는 0.1도보다 높다는 것을 이해할 수 없다는 것입니다. [25]에서는 일반적인 분류 알고리즘이 클래스 분류에서 정보에 순서를 적용하는 것이 가능하도록 하는, 서수 분류(oridnal classification)라고 알려진 간단한 방법을 소개합니다. 이 아이디어는 ordinal regression problem을 더 작고 간단한 이진 분류 문제(binary classification)들로 변환하는 것입니다. 이로부터 영감을 받아, [26]에서는 이 아이디어를 CNNs를 사용하여 나이 추정을 위해 간단한 이진 분류 문제 해결에 적용하였습니다.
우리에게 주어진 회전과 병진 클래스들을 작은 이진 분류 문제들로 변환하기 위해서는 데이터셋을 레이블링 하는 방법을 바꿔야 합니다. ground truth를 나타내는 클래스를 직접적으로 레이블링 하는 대신, 샘플들은 rank라고 하는 ordinal scale로 레이블 되어야 합니다. $k$를 가능한 클래스의 숫자라고 하면, 주어진 문제를 $k-1$개의 이진 분류 문제로 바꿀 수 있습니다. 구체적으로 말하자면, 각 subproblem의 한 샘플 $i$은 $l^k_i \in0, 1$으로 레이블링 되며, 이는 샘플 클래스 $l_i$가 아래 식과 같이 $r_k$보다 큰지 아닌지를 가리킵니다.

rank 포맷은 한 값이 다른 것들보다 작은지 큰지를 보여주는 것에 의해 네트워크가 클래스의 순서를 학습할 수 있도록 해줍니다. ordinal classification labeling 과정의 요약은 그림 3과 같습니다.

이진 분류 subproblems를 풀기 위해서는, 손실 함수는 타깃 값과 출력된 회전 및 병진값에 대한 이진 크로스 엔트로피(Binart Cross Entropy)로 정의합니다.

$d$와 $\theta$는 relative ground-truth translation 및 rotation rank labels이고, $\hat{d}$과 $\hat{\theta}$는 네트워크의 출력입니다. $\hat{d}$과 $\hat{\theta}$는 손실 함수에 사용되기 전에 시그모이드 함수를 통과합니다. 위 식에서 사용된 $\beta$는 회전과 병진 손실값의 스케일 차이에 대한 균형을 맞추기 위한 파라미터입니다.
본 논문에서는 제안된 네트워크를 파이토치를 사용하여 구현하였으며, 옵티마이저는 Adam, 학습률은 0.0001입니다. 또한, [12]에서 권장되듯이, CNN-Cam의 사전 훈련 시, 훈련 시간을 줄이기 위해서 사전 훈련된 FlowNet 모델의 가중치를 사용하였습니다.
[4] Altché, Florent, and Arnaud De La Fortelle. "An LSTM network for highway trajectory prediction." Intelligent Transportation Systems (ITSC), 2017 IEEE 20th International Conference on. IEEE, 2017.
[5] Wirges, Sascha, et al. "Object detection and classification in occupancy grid maps using deep convolutional networks." 2018 21st International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2018.
[6] Jaritz, Maximilian, et al. "End-to-end race driving with deep reinforcement learning." 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018.
[7] Devineau, Guillaume, et al. "Coupled Longitudinal and Lateral Control of a Vehicle using Deep Learning." 2018 21st International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2018.
[8] Scaramuzza, Davide, and Friedrich Fraundorfer. "Visual odometry [tutorial]." IEEE robotics & automation magazine 18.4 (2011): 80-92.
[9] Mur-Artal, Raul, Jose Maria Martinez Montiel, and Juan D. Tardos. "ORB-SLAM: a versatile and accurate monocular SLAM system." IEEE Transactions on Robotics 31.5 (2015): 1147-1163.
[10] Forster, Christian, Matia Pizzoli, and Davide Scaramuzza. "SVO: Fast semi-direct monocular visual odometry." Robotics and Automation (ICRA), 2014 IEEE International Conference on. IEEE, 2014.
[11] Kendall, Alex, Matthew Grimes, and Roberto Cipolla. "Posenet: A convolutional network for real-time 6-dof camera relocalization." Proceedings of the IEEE international conference on computer vision. 2015.
[12] Wang, Sen, et al. "Deepvo: Towards end-to-end visual odometry with deep recurrent convolutional neural networks." Robotics and Automation (ICRA), 2017 IEEE International Conference on. IEEE, 2017.
[13] Li, Ruihao, et al. "Undeepvo: Monocular visual odometry through unsupervised deep learning." 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018.
[14] BESL, Paul J. et MCKAY, Neil D. Method for registration of 3-D shapes. In : Sensor Fusion IV: Control Paradigms and Data Structures. International Society for Optics and Photonics, 1992. p. 586-607.
[15] Zhang, Ji, and Sanjiv Singh. "LOAM: Lidar Odometry and Mapping in Real-time." Robotics: Science and Systems. Vol. 2. 2014.
[16] Nicolai, Austin, et al. "Deep learning for laser based odometry estimation." RSS workshop Limits and Potentials of Deep Learning in Robotics. 2016.
[17] Li, Jiaxin, et al. "Deep learning for 2D scan matching and loop closure." Intelligent Robots and Systems (IROS), 2017 IEEE/RSJ International Conference on. IEEE, 2017.
[18] Velas, Martin, et al. "CNN for IMU assisted odometry estimation using velodyne LiDAR." Autonomous Robot Systems and Competitions (ICARSC), 2018 IEEE International Conference on. IEEE, 2018.
[19] Valente, Michelle, Cyril Joly, and Arnaud de la Fortelle. "An LSTM Network for Real-time Odometry Estimation". arXiv preprint arXiv:1902.08536 (2019).
[20] Valente, Michelle, Cyril Joly, and Arnaud de La Fortelle. "Fusing Laser Scanner and Stereo Camera in Evidential Grid Maps." 2018 15th International Conference on Control, Automation, Robotics and Vision (ICARCV). IEEE, 2018.
[21] Gleichauf, Johanna, Christian Pfitzner, and Stefan May. "Sensor Fusion of a 2D Laser Scanner and a Thermal Camera." (2017).
[22] Xu, Danfei, Dragomir Anguelov, and Ashesh Jain. "Pointfusion: Deep sensor fusion for 3d bounding box estimation." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[23] Patel, Naman, et al. "Sensor modality fusion with CNNs for UGV autonomous driving in indoor environments." 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2017.
[24] Grisetti, Giorgio, et al. "A tutorial on graph-based SLAM." IEEE Intelligent Transportation Systems Magazine 2.4 (2010): 31-43.
[25] Li, Ling, and Hsuan-Tien Lin. "Ordinal regression by extended binary classification." Advances in neural information processing systems. 2007.
[26] Niu, Zhenxing, et al. "Ordinal regression with multiple output cnn for age estimation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[27] Hochreiter, Sepp, and Jürgen Schmidhuber. "Long short-term memory." Neural computation 9.8 (1997): 1735-1780.
[28] Pascanu, Razvan, Tomas Mikolov, and Yoshua Bengio. "On the difficulty of training recurrent neural networks." International Conference on Machine Learning. 2013.
[29] A. Dosovitskiy, P. Fischery, E. Ilg, C. Hazirbas, V. Golkov, P. van der Smagt, D. Cremers, T. Brox et al., “Flownet: Learning optical flow with convolutional networks,” in Proceedings of IEEE InternationalConference on Computer Vision (ICCV). IEEE, 2015, pp. 2758–2766.