Path Planning Basics: Dijkstra Algorithm
이 포스트는 theconstructsim.com의 Path Planning Basics: Dijkstra Algorithm 를 참고하였습니다.
https://www.youtube.com/watch?v=ZmQIkBws4LA
1. The problem to solve
이번 챕터에서는 먼저 로봇이 점유 격자 지도(occupancy grid map)을 이미 가지고 있고, 오차 없이 자신의 위치를 정확하게 알 수 있다고 가정하겠습니다. 추가적으로, 로봇의 시작 위치와 목표 위치 또한 주어져 있다고 생각할 것입니다.
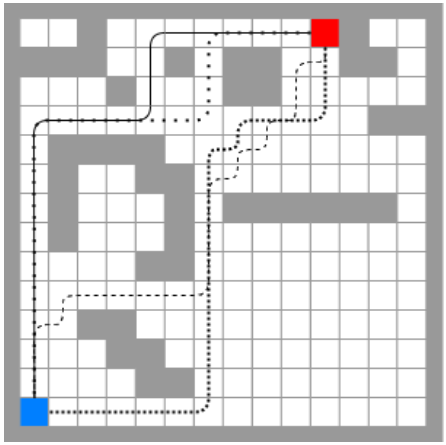
위의 지도에서 하얀 cell은 free space, 어두운 부분은 장애물을 의미합니다. 위 그림과 같이 주어진 공간에서 로봇은 인접한 free grid cells로만 이동 가능하며, 지도 경계 밖으로 나갈 수 없습니다.
여기서 직면하는 문제는, 로봇이 목표 위치로 도달하기 위해 따라가야 할 waypoints의 시퀀스는 무엇인가? 입니다. 위 그림에서 볼 수 있듯이, 14x14 공간 안에서 로봇이 파란색 셀 부터 빨간 셀로 이동하기위해 사용할 수 있는 경로는 매우 많습니다. 하지만 우리가 원하는 것은 목표지점으로 도달하기 위한 가장 짧은 경로입니다.
중요한 가정:
- 로봇은 지도를 갖고 있습니다.
- 로봇은 자신의 위치를 추정할 수 있습니다.
- 환경은 변하지 않습니다.
- 로봇은 free space에서 상하좌우로만 움직일 수 있습니다.
시뮬레이션에서 사용할 환경은 다음과 같습니다.

2. Step by step example

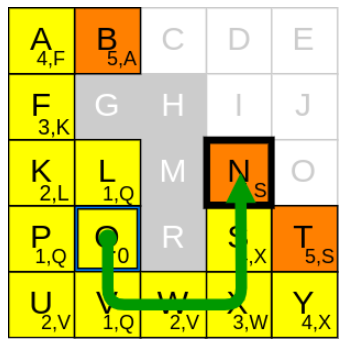
위 그림과 같이 5x5 grid map에서의 다익스트라 알고리즘을 알아보겠습니다. 우리가 알고 싶은 경로는 시작 위치 Q에서 목표 위치 N 까지의 최단경로입니다.
알고리즘의 시작
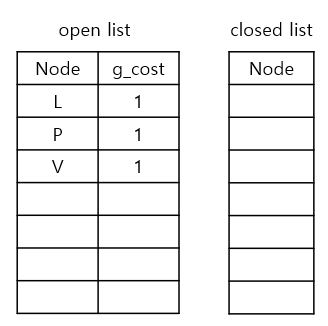
다익스트라 알고리즘에서 key component는 출발 지점으로부터 각각의 cell로 가는 최단 경로를 항상 추적하는 것입니다. 우리는 그 최단경로 값을 g_cost라고 할 것이며, 이 값을 각 셀의 오른쪽 하단부에 표시할 것입니다. 프로세스를 시작하기 전에, 시작 지점(node Q)의 g_cost는 0으로 설정합니다. 그리고 알고리즘이 시작되면, 각 셀의 g_cost들은 시작 노드로부터의 최단경로 값으로 업데이트 될 것입니다. 그리고, 시작하면서 node Q를 open list(방문해야 할 노드)에 추가합니다. open list는 주황색으로 표시합니다.


알고리즘 반복 단계
1) 현재 node 선택
반복되는 탐색 과정은 open list에서 g_cost가 가장 작은 노드를 선택하는것으로 부터 시작합니다. 우리는 이 node를 current node라고 할 것입니다. 일단 지금 단계에서 open list에는 node Q밖에 없습니다. 우리는 current node를 굵은 테두리로 표시할 것입니다.

2) 현재 node의 이웃(neighbours)
그 다음으로 해야할 것은 current node와 인접한 직접적인 neighbours를 확인하는 것입니다. 이 예시에서는 앞서 언급했듯이 로봇이 상하좌우로만 움직인다고 가정합니다. 현재 node의 neighbours는 current node로부터 화살표에 의해 나타내어집니다.
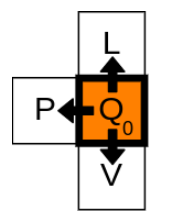
3) 지금까지 이동한 거리를 업데이트하고, parent node를 저장
free space의 모든 neighbour를 식별하고 나면, 우리는 그 neighbour의 g_cost를 업데이트 해야합니다. 그 다음으로, 각 neigubour의 parent node를 지정해줍니다. 여기서 말하는 parent는 업데이트된 g_cost가 온 곳의 node를 의미합니다. 우리는 그림에서 각 cell의 parent node를 g_cost 옆에 표시할 것입니다. 그리고, 각각의 neighbour를 open list에 넣습니다.
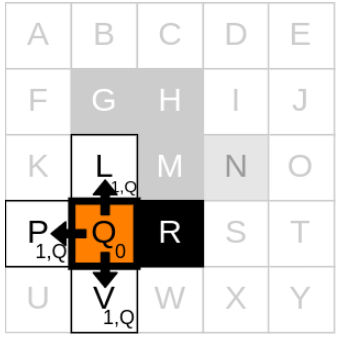
node Q의 이웃에 대한 처리 과정을 자세히 알아보겠습니다.
먼저 neighbour L에 대한 처리를 시작할 것인데, 순서는 상관 없습니다. P 또는 V먼저 해도 상관 없습니다.
1. current node의 g_cost에다가 step-cost를 더한 값을 neighbor cell에 할당해줍니다. 지금 예시에서는 상하좌우로만 이동할 수 있고, 각 칸을 이동할때의 step-cost를 1이라고 가정할 것입니다. current node는 Q였고, Q의 g_cost는 0이므로, L의 g_cost는 1입니다.
2. L의 parent node를 Q로 할당합니다.
3. Q를 open list에 넣습니다.
이제 인접한 다른 neighbour인 P와 V에 대해서도 똑같이 적용합니다.
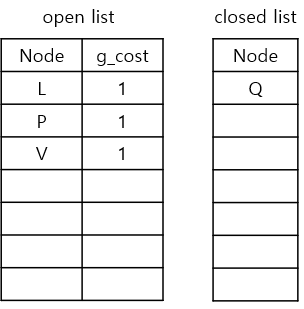
이제 Q에 대한 모든 과정을 마쳤으니, Q는 closed list(방문한 node)에 추가합니다. 그리고 이 node는 노란색으로 표시할 것입니다.
다익스트라 알고리즘은 위의 과정을 반복합니다. 1) 새로운 current node를 고르고, 2) neighbours를 확인하고, 3) g_cost와 parent node를 업데이트
이제 새로운 반복 사이클의 시작 부분을 확인해보겠습니다. 여기서 가장 먼저 할 것은 새로 탐험할 current node를 선택하는 것, 즉 1) 새로운 current node 고르기 단계 입니다. 우리는 open list에 있는 node 중에서 g_cost가 가장 낮은 node를 선택할 것입니다. 지금 open_list에 있는 g_cost가 가장 작은 node들은 L, P, V이며 g_cost는 모두 1로 같습니다. 따라서 그냥 아무거나 선택해도 상관은 없습니다. 이번 예시에서는 L을 먼저 current node로 정해보겠습니다.
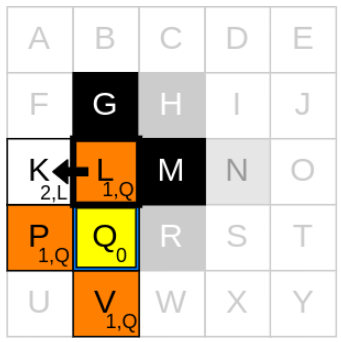
다음으로 해야할 것은 2) neighbours를 확인하기 입니다. G와 M은 장애물이고, Q는 closed list에 들어있으므로 무시합니다. 그럼 남은것은 K 뿐이네요
그 다음은 3) g_cost와 parent node를 업데이트하기 입니다. 다음과 같은 과정을 거칩니다.
1. current node인 L의 g_cost(1)에 step-cost(1)를 더하기
2. 1.에서 구한 값을 K의 g_cost(1+1)로 업데이트 하기
3. current node를 K의 parent node로 업데이트 하기
4. K를 open list에 추가하기
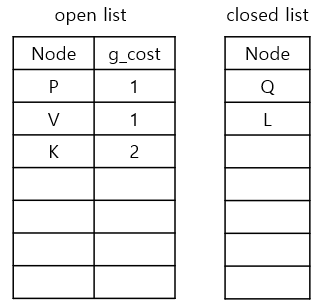
마지막으로, current node인 L을 closed-list에 추가하면 끝입니다.
반복 단계 3
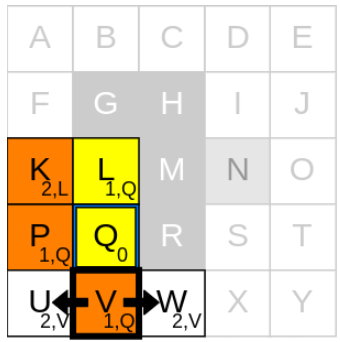
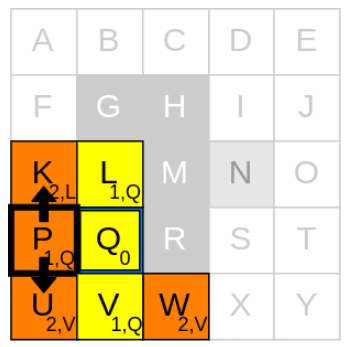
앞서 언급했듯이, 1) 새로운 current node를 고르고, 2) neighbours를 확인하고, 3) g_cost와 parent node를 업데이트 중에서 새로운 current node를 고를 차례입니다. 우리는 P 또는 V 중에 아무거나 선택할 것입니다. 예를 들어 V를 선택했다고 가정하면, 가능한 neighbour은 U와 W가 있습니다. 만약 U를 먼저 처리한다고 하면,
1. currnet node인 V의 g_cost(1)에 step-cost(1) 더하기
2. 1.에서 구한 값을 U의 g_cost(1+1)로 업데이트하기
3. current node V를 parent node로 업데이트하기
4. U를 open list에 추가하기
위의 단계를 W에도 반복하고, 마지막으로 current node인 V를 closed list에 추가해주면 됩니다.
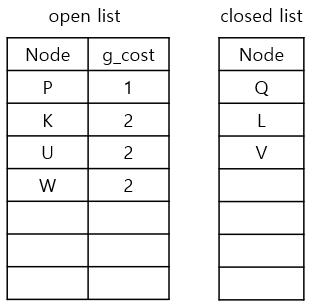
반복 단계 4
1) 새로운 current node 고르기
g_cost가 가장 낮은 node는 P 뿐이므로, P를 current node로 정합니다.
2) neighbours를 확인하기
P에서 neighbours를 탐색해보니 Q는 closed list에 있고, K와 U는 이미 g_cost를 가지고 있습니다.
3) g_cost와 parent node를 업데이트
이런 경우에는 P에서 이동하는 경우에 대한 g_cost값과 비교해서, 만약 기존의 g_cost보다 새로운 g_cost가 더 낮은 경우에는 새로운 node에 대한 값들로 업데이트 하고, 만약 두 값이 같거나 기존 값이 더 낮다면 업데이트하지 않습니다.
예를들어 current node가 P이고, neighbour K를 선택한 경우에 대해 생각해보겠습니다.
1. currnet node인 P의 g_cost(1)에 step-cost(1) 더하기
2. 1.에서 구한 값 g_cost(1+1)와 K의 g_cost(2) 비교하기
3. 만약 K의 g_cost보다 낮다면 g_cost와 parent를 업데이트 하기. 아니라면 그대로 둔다
4. 만약 3.에서 업데이트 했다면 새로 업데이트된 g_cost와 parent를 open_list에 추가하기
위 과정이 끝나면 P를 closed list에 추가합니다
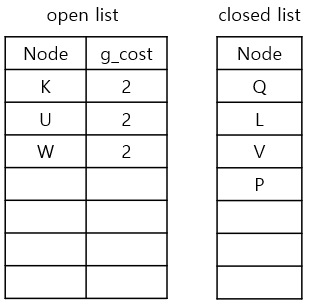
반복 단계 5
1) 새로운 current node 고르기
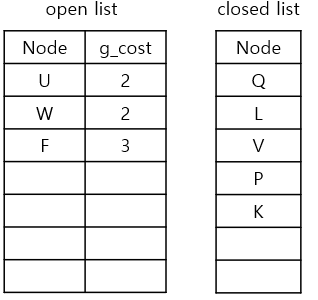
g_cost가 가장 낮은 node는 K, U, W인데, K를 먼저 생각해보겠습니다.
2) neighbours를 확인하기
K에서 neighbours를 탐색해보니 P는 이미 closed list에 있으므로, 가능한 이웃은 F입니다.
3) g_cost와 parent node를 업데이트
1. currnet node인 K의 g_cost(2)에 step-cost(1) 더하기
2. 1.에서 구한 값을 F의 g_cost(2+1)로 업데이트하기
3. current node K를 F의 parent node로 업데이트하기
4. F를 open list에 추가하기
5. current node K를 closed list에 추가하기
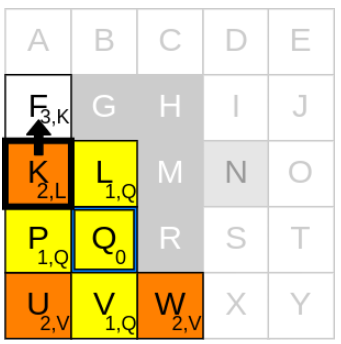
반복 단계 6
1) 새로운 current node 고르기
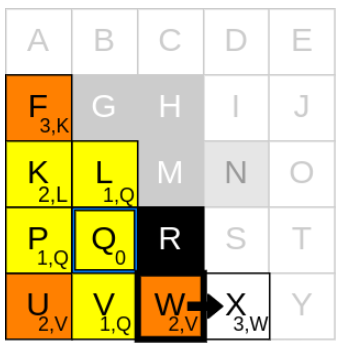
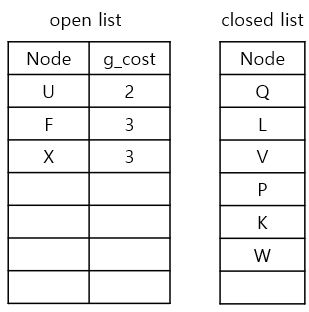
g_cost가 가장 낮은 node는 U, W인데, W를 먼저 생각해보겠습니다.
2) neighbours를 확인하기
W에서 neighbours를 탐색해보니 V는 이미 closed list에 있으므로, 가능한 이웃은 X입니다.
3) g_cost와 parent node를 업데이트
1. currnet node인 W의 g_cost(2)에 step-cost(1) 더하기
2. 1.에서 구한 값을 X의 g_cost(2+1)로 업데이트하기
3. current node W를 X의 parent node로 업데이트하기
4. X를 open list에 추가하기
5. current node W를 closed list에 추가하기
반복 단계 7
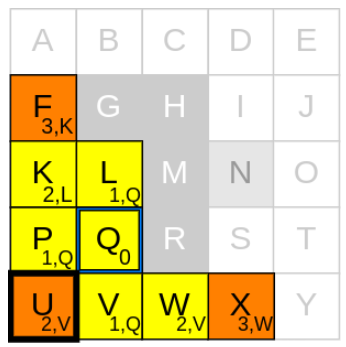
1) 새로운 current node 고르기
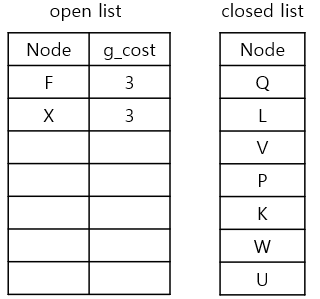
g_cost가 가장 낮은 node는 U입니다.
2) neighbours를 확인하기
U에서 neighbours를 탐색해보니 P, V는 이미 closed list에 있으므로, 가능한 이웃은 없습니다.
3) g_cost와 parent node를 업데이트
이동 가능한 neighbours가 없으므로, current node인 U를 closed list에 추가합니다.
반복 단계 8
1) 새로운 current node 고르기
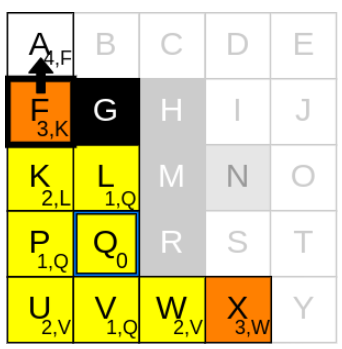
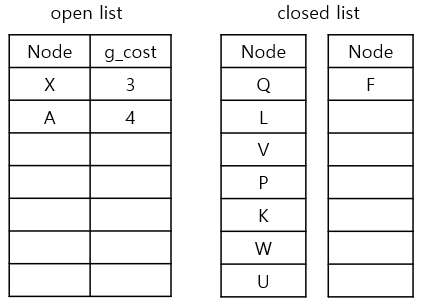
g_cost가 가장 낮은 node는 F, X인데 F를 먼저 고려해보겠습니다
2) neighbours를 확인하기
F에서 neighbours를 탐색해보니 가능한 이웃은 A입니다.
3) g_cost와 parent node를 업데이트
1. currnet node인 F의 g_cost(3)에 step-cost(1) 더하기
2. 1.에서 구한 값을 A의 g_cost(3+1)로 업데이트하기
3. current node F를 A의 parent node로 업데이트하기
4. A를 open list에 추가하기
5. current node F를 closed list에 추가하기
반복 단계 9
1) 새로운 current node 고르기
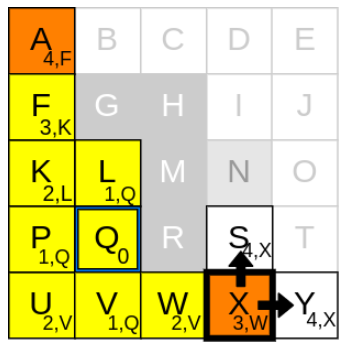
g_cost가 가장 낮은 node는 X입니다
2) neighbours를 확인하기
X에서 neighbours를 탐색해보니 가능한 이웃은 S, Y입니다
3) g_cost와 parent node를 업데이트
1. currnet node인 X의 g_cost(3)에 step-cost(1) 더하기
2. 1.에서 구한 값을 S, Y의 g_cost(3+1)로 업데이트하기
3. current node X를 S, Y의 parent node로 업데이트하기
4. S, Y를 open list에 추가하기
5. current node X를 closed list에 추가하기
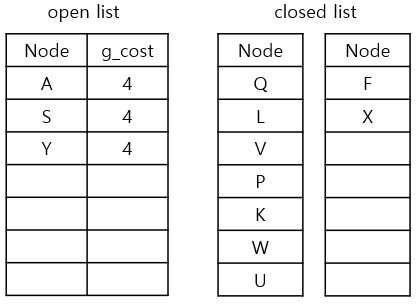
반복 단계 10
1) 새로운 current node 고르기
g_cost가 가장 낮은 node는 A, S, Y입니다. 먼저 A에 대해 생각해봅니다
2) neighbours를 확인하기
A에서 neighbours를 탐색해보니 가능한 이웃은 B입니다
3) g_cost와 parent node를 업데이트
1. currnet node인 A의 g_cost(4)에 step-cost(1) 더하기
2. 1.에서 구한 값을 B의 g_cost(4+1)로 업데이트하기
3. current node A를 B의 parent node로 업데이트하기
4. B를 open list에 추가하기
5. current node A를 closed list에 추가하기
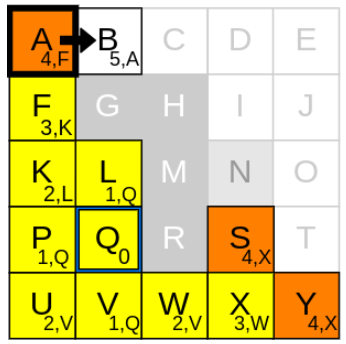
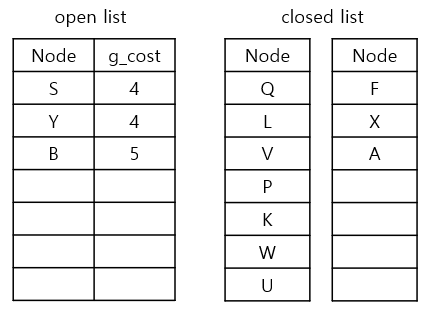
반복 단계 11
1) 새로운 current node 고르기
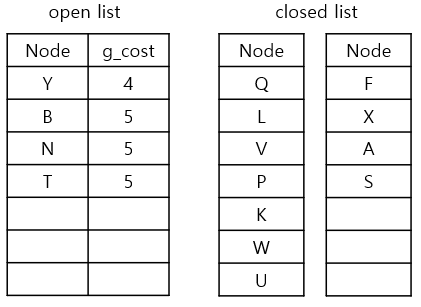
g_cost가 가장 낮은 node는 S, N입니다. 먼저 S에 대해 생각해봅니다
2) neighbours를 확인하기
S에서 neighbours를 탐색해보니 가능한 이웃은 N, T입니다
3) g_cost와 parent node를 업데이트
1. currnet node인 S의 g_cost(4)에 step-cost(1) 더하기
2. 1.에서 구한 값을 N, T의 g_cost(4+1)로 업데이트하기
3. current node S를 N, T의 parent node로 업데이트하기
4. N, T를 open list에 추가하기
5. current node S를 closed list에 추가하기
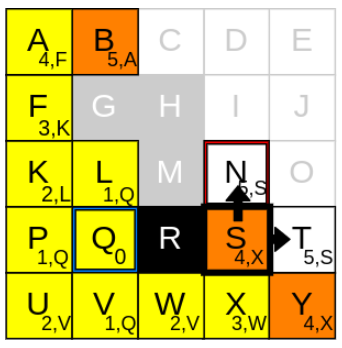
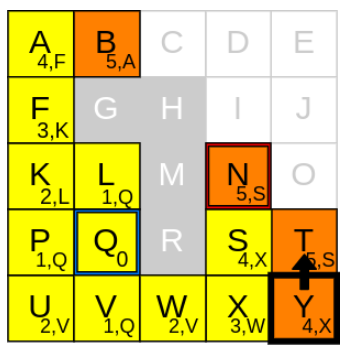
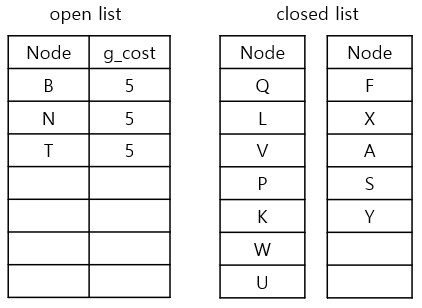
반복 단계 12
1) 새로운 current node 고르기
g_cost가 가장 낮은 node는 Y입니다.
2) neighbours를 확인하기
Y에서 neighbours를 탐색해보니 가능한 이웃은 T입니다
3) g_cost와 parent node를 업데이트
1. currnet node인 Y의 g_cost(4)에 step-cost(1) 더하기
2. 1.에서 구한 값 g_cost(4+1)와 T의 g_cost(5) 비교하기
3. 만약 T의 g_cost보다 낮다면 g_cost와 parent를 업데이트 하기. 아니라면 그대로 둔다
4. 만약 3.에서 업데이트 했다면 새로 업데이트된 g_cost와 parent를 open_list에 추가하기
5. current node Y를 closed list에 추가하기
반복 단계 13
1) 새로운 current node 고르기
g_cost가 가장 낮은 node는 B, N, T인데 그중에 N을 선택해보겠습니다.
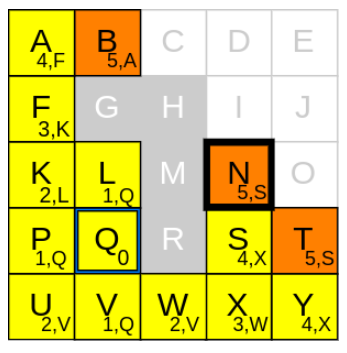
그런데 목표지점이네요. 하지만 아직 완전히 끝난건 아닙니다. 다익스트라 알고리즘은 2개의 페이즈로 나뉩니다.
1. 지도를 탐험하며 데이터 모으기
2. 수집된 데이터를 사용하여 최단경로 생성하기
우리는 이제 막 1페이즈를 끝낸 것입니다.
지금까지 neighbors와 어떤 node가 다른 node의 parent가 되는지에 대한 결정을 하면서, free space들이 어떻게 연결되어있는지에 대한 정보를 얻었습니다. 또한, 목표지점에 도달할 수 있는 경로가 있다는 것도 확인했습니다. 하지만 아직 그 경로가 어떤 경로인지는 확인하지 못했으니, 이제 확인해볼 것입니다.
최단경로 만들기
target node에 도착하고 나면, 우리는 target node로부터의 parent node를 따라가면 최단경로를 찾을 수 있습니다.
따라서, 먼저 target node N을 새로운 리스트에 추가하고, 그 parent node를 찾으면 됩니다. N의 parent node는 S이고, S의 parent node는 X입니다. 이런식으로 시작 node인 Q를 찾을때까지 따라가면 됩니다.
순서가 반대이므로, 그냥 뒤집으면 됩니다.
즉, 주어진 조건에서의 최단경로는 다음과 같습니다.
3. 다익스트라 알고리즘 요약
path planning은 exploration process입니다. 이는 연결된 노드들을 탐색하는것에 의해 최단거리를 찾는 문제를 해결해줍니다.
이 탐색을 진행하는 동안, 알고리즘은 current node로써 하나의 노드를 유지하는데, 이 node는 탐색 절차에 따라 변하게 됩니다. 이 알고리즘은 시작 node로부터 새롭게 발견된 node들에 의해 확장되며, 이 node들을 다음에 탐험할 수 있는 node의 리스트에 추가합니다. 이 단계는 find neighbours라고 불립니다. 기본적으로, neighbours는 current node로부터 접근 가능한 모든 node들입니다.
여기서 우리가 사용할 리스트는
- open list(unvisited node 또는 frontier라고도 함)
- closed list(visited node라고도 함)
open list의 node들은 neighbours로써 발견되었지만, 아직 current node로 선택되지는 않은 node들입니다. closed list의 node들은 완전히 처리가 끝난 node들입니다. closed list는 알고리즘이 같은 작업을 반복해서 탐색 시간이 overhead되지 않도록 하기 위한 목적으로 사용됩니다.
최단거리를 찾기 위해 우리는 g_cost와 parent node라는 변수를 사용할 것입니다. g_cost는 시작 node로부터 특정한 node까지 움직이기 위해 필요한 비용(cost)입니다. 이는 어떤 parent까지의 g_cost와 그 parent로부터 다른 node로 이동하기 위한 step-cost를 더하는 것으로 계산합니다. 다익스트라 알고리즘은 open list에서 current node를 선택하기 위해 가장 낮은 g_cost를 우선적으로 선택합니다.
4. 일반적인 다익스트라 알고리즘
초기 설정
1. 초기 node의 g_cost를 0으로 설정하고, 이 초기 node를 open_list에 추가합니다
1페이즈 :
open_list에 요소가 없을 때까지 다음을 반복합니다
1. open_list에서 g_cost가 가장 낮은 node를 추출하여 current_node로 설정합니다
2. current_node를 closed_list에 추가합니다
3. current_node가 target node라면 2페이즈로 넘어갑니다. 아니라면 다음 단계를 진행합니다
4. current_node의 neighbours를 찾습니다.
current_node의 모든 neighbours에 대해 다음을 진행합니다
- 만약 선택된 neighbour가 closed_list에 있다면, 다른 neighbour를 선택합니다
- 만약 선택된 neighbour가 open_list에 있다면, 새로운 g_cost와 기존의 g_cost를 비교해서, 새로운 g_cost값이 더 낮다면 g_cost와 parent를 업데이트합니다
- 만약 선택된 neighbour가 open_list에 없다면, g_cost와 parent를 업데이트 하고, open_list에 추가합니다
current_node의 모든 neighbour에 대한 처리가 끝나면, 2페이즈로 넘어갑니다
2페이즈:
target node로부터 parent node를 따라가며 최단경로를 찾습니다.
5. 파이썬 다익스트라 알고리즘의 구현
이 코드는 다음과 같은 grid에 넘버링이 되어있는 환경에서 실행된다고 생각하시면 됩니다. 또한 대각선 방향의 이동도 고려합니다.
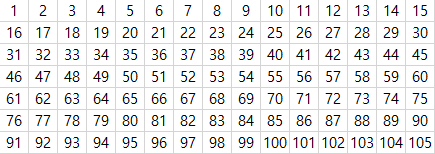
주어진 지도의 width는 15, height는 7입니다. 만약 현재 로봇의 위치가 55라고 했을 때, 로봇이 움직일 수 있는 위치는 다음과 같습니다
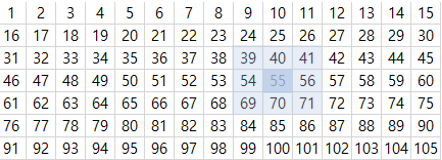
로봇의 11시방향, 즉 39는 (현재 로봇의 위치 - width - 1)입니다.
로봇의 12시방향, 즉 40은 (현재 로봇의 위치 - width) 입니다.
로봇의 1시방향, 즉 41은 (현재 로봇의 위치 - width + 1)입니다.
이런 식으로 현재 로봇 위치의 neighbours를 계산할 수 있습니다.
이 내용을 머릿속에 담아두고, 일단 전체 코드를 확인해보겠습니다.
#! /usr/bin/env python
"""
Dijkstra's algorithm path planning exercise
Author: Roberto Zegers R.
Copyright: Copyright (c) 2020, Roberto Zegers R.
License: BSD-3-Clause
Date: Nov 30, 2020
Usage: roslaunch unit2 unit2_exercise.launch
"""
import rospy
def find_neighbors(index, width, height, costmap, orthogonal_step_cost):
"""
Identifies neighbor nodes inspecting the 8 adjacent neighbors
Checks if neighbor is inside the map boundaries and if is not an obstacle according to a threshold
Returns a list with valid neighbour nodes as [index, step_cost] pairs
"""
neighbors = []
# length of diagonal = length of one side by the square root of 2 (1.41421)
diagonal_step_cost = orthogonal_step_cost * 1.41421
# threshold value used to reject neighbor nodes as they are considered as obstacles [1-254]
lethal_cost = 1
upper = index - width
if upper > 0:
if costmap[upper] < lethal_cost:
step_cost = orthogonal_step_cost + costmap[upper]/255
neighbors.append([upper, step_cost])
left = index - 1
if left % width > 0:
if costmap[left] < lethal_cost:
step_cost = orthogonal_step_cost + costmap[left]/255
neighbors.append([left, step_cost])
upper_left = index - width - 1
if upper_left > 0 and upper_left % width > 0:
if costmap[upper_left] < lethal_cost:
step_cost = diagonal_step_cost + costmap[upper_left]/255
neighbors.append([index - width - 1, step_cost])
upper_right = index - width + 1
if upper_right > 0 and (upper_right) % width != (width - 1):
if costmap[upper_right] < lethal_cost:
step_cost = diagonal_step_cost + costmap[upper_right]/255
neighbors.append([upper_right, step_cost])
right = index + 1
if right % width != (width + 1):
if costmap[right] < lethal_cost:
step_cost = orthogonal_step_cost + costmap[right]/255
neighbors.append([right, step_cost])
lower_left = index + width - 1
if lower_left < height * width and lower_left % width != 0:
if costmap[lower_left] < lethal_cost:
step_cost = diagonal_step_cost + costmap[lower_left]/255
neighbors.append([lower_left, step_cost])
lower = index + width
if lower <= height * width:
if costmap[lower] < lethal_cost:
step_cost = orthogonal_step_cost + costmap[lower]/255
neighbors.append([lower, step_cost])
lower_right = index + width + 1
if (lower_right) <= height * width and lower_right % width != (width - 1):
if costmap[lower_right] < lethal_cost:
step_cost = diagonal_step_cost + costmap[lower_right]/255
neighbors.append([lower_right, step_cost])
return neighbors
def dijkstra(start_index, goal_index, width, height, costmap, resolution, origin, grid_viz=None):
'''
Performs Dijkstra's shortes path algorithm search on a costmap with a given start and goal node
'''
#### To-do: complete all exercises below ####
open_list = [[start_index, 0]]
closed_list = set()
parents = {}
g_costs = {}
shortest_path = []
g_costs[start_index] = 0
path_found = False
rospy.loginfo('Dijkstra : Done with initialization')
while open_list:
open_list.sort(key=lambda x: x[1])
current_node = open_list.pop(0)[0]
closed_list.add(current_node)
grid_viz.set_color(current_node, "pale yellow")
if current_node == goal_index:
path_found = True
break
neighbours = find_neighbors(
current_node, width, height, costmap, resolution)
for neighbor_index, step_cost in neighbours:
if neighbor_index in closed_list:
continue
g_cost = g_costs[current_node] + step_cost
in_open_list = False
for idx, element in enumerate(open_list):
if element[0] == neighbor_index:
in_open_list = True
break
if in_open_list:
if g_cost < g_costs[neighbor_index]:
g_costs[neighbor_index] = g_cost
parents[neighbor_index] = current_node
open_list[idx] = [neighbor_index, g_cost]
else:
g_costs[neighbor_index] = g_cost
parents[neighbor_index] = current_node
open_list.append([neighbor_index, g_cost])
grid_viz.set_color(neighbor_index, 'orange')
rospy.loginfo('Dijkstra: Done traversing nodes in open_list')
if not path_found:
rospy.logwarn('Dijkstra: No path found!')
return shortest_path
if path_found:
node = goal_index
shortest_path.append(goal_index)
while node != start_index:
shortest_path.append(node)
# get next node
node = parents[node]
# reverse list
shortest_path = shortest_path[::-1]
rospy.loginfo('Dijkstra: Done reconstructing path')
return shortest_path

위 그림에서 주황색은 open_list, 노란색은 closed_list 입니다.
6. 다익스트라 알고리즘의 한계
다익스트라 알고리즘은 blind search라고도 하는, uninformed search 알고리즘입니다. 즉, expansion process를 진행하는 동안, 어떤 grid cell이 다른 grid cell보다 더 나은지 알 수 없습니다. 따라서 이 알고리즘은 시작 node로부터 가능한 모든 방향을 탐색하게 되므로, informed search 전략보다 많은 시간을 소비하게 됩니다.
이는 지도의 크기가 커질수록 더 큰 문제가 됩니다. 시간 뿐 아니라 알고리즘이 진행되며 탐색 구역을 확장할수록 요구되는 메모리도 증가하게 됩니다.
또한 다익스트라 알고리즘은 주변 환경이 동적(dynamic)이 아닌, 정적(static)이라고 가정합니다. 이는 다익스트라 알고리즘이 고정된 경로(rigid path)를 만들어낸다는 것입니다. 그 결과, 만약 환경이 바뀌게 되면 로봇이 기존에 만들었던 경로는 더이상 필요가 없게될 수도 있다는 것입니다. 이를 해결하는 방법 중 하나는 계속적으로 경로를 다시 계산하는 것입니다.
또한 이 외에도 로봇의 시작 방향, 최소 회전 반경, 속도, 가속도 제한 등등 여러 다른 변수를 고려하지 않은 알고리즘이라는 것을 기억해두세요.